


システム開発で、データベース設計に取り組む際、考え方がわからず戸惑うことがよくあります。本記事では、データベース設計の基本的な流れとポイントを丁寧に解説します。
具体的には、データベースの種類、設計の手順や大事なポイントから、ツールの選び方や外注する際の注意点など、データベース初心者に向けた情報をわかりやすく提供します。
本記事を参考にすることで、データベース設計の全体像をつかむことができます。自信を持って、設計に取り組めるようになるでしょう。
データベース設計経験が浅い方におすすめの入門記事ですので、ぜひ一読してください。
現役のシステムエンジニアとして10年程度のキャリアがあります。 Webシステム開発を中心に、バックエンドからフロントエンドまで幅広く対応してきました。 最近はAIやノーコードツールも触っています。
データベース設計とは
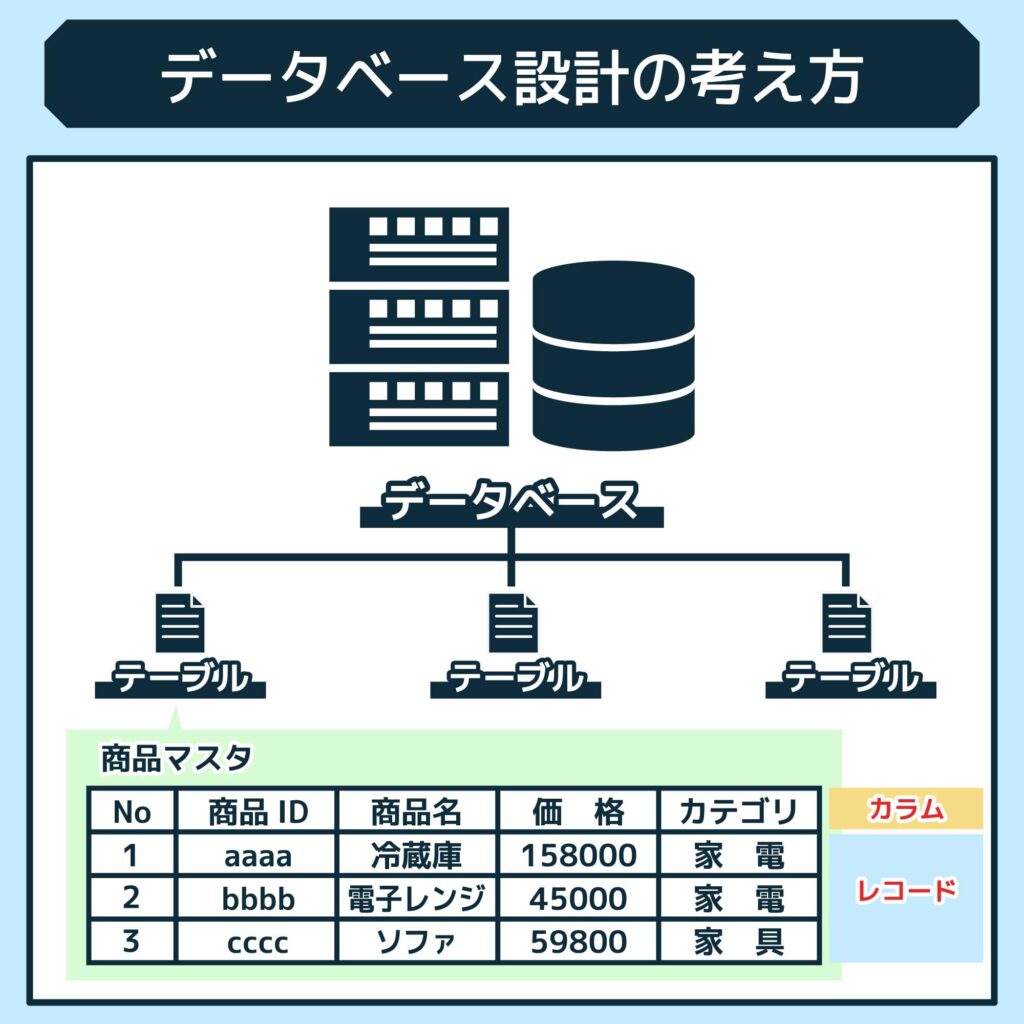
データベースを作るにあたって、事前にしっかりと設計を行うことが非常に大切です。ここでは、データベース設計の基本的な考え方について解説します。
データベース設計とは
データベース設計とは、目的とするシステムで扱うデータ項目やテーブル構成を、事前に計画する作業のことです。
データベース設計には大きく分けて、ビジネスルールやデータ項目の洗い出しからテーブル定義、キー設計、正規化等の作業が含まれます。
データベースが受け持つ機能要件を、正しく理解した上で、扱うデータを洗い出し、適切にテーブルにまとめていく作業がポイントとなります。
あらかじめ、データ構造やテーブル定義を詳細に検討しておくことで、開発工数の削減やデータの整合性確保など、さまざまなメリットが生まれます。しっかりと時間をかけて、設計を行う意義は大きいです。
論理設計と物理設計の違い
データベース設計には、大きく論理設計と物理設計の2つの段階があります。
| 比較項目 | 論理設計 | 物理設計 |
| 着目点 | データ構造の概念設計 | 物理的なデータ配置 |
| 主な作業 | ・エンティティ抽出
・属性定義 ・テーブル関連性設計 |
・主キー設定
・インデックス設計 ・テーブルスペース設計 ・パーティショニング |
| 目的 | 概念と実装のギャップ回避 | 性能、拡張性を考慮したデータ配置 |
| 成果物 | 論理データモデル(ER図) | 物理テーブル定義書 |
論理設計は、先ほどのデータ項目とテーブルの関連性に着目し、概念的なデータ構造を立てる作業です。
具体的には、ビジネス上のルールや機能要件から取り扱うデータ項目を洗い出し、テーブルの抽出、属性の定義、テーブル間の関連性の決定といった工程を踏みます。
一方物理設計は、実際にDBMS(データベース管理システム)上でデータベースを構築することを想定し、テーブルの物理的な仕様を設計することです。主キーやインデックスの設定、パーティショニングの設定、テーブルスペースの設計などデータベースの物理的な配置を決めていきます。
この論理から物理へ、2つの段階を経ることで、概念と実装の間にギャップが生じることなく、システム要件に適した最適なデータベース設計を行うことができます。
代表的なデータベースの種類

データベースには、データの構造や管理方法によって様々な種類があります。システムの要件やデータの特性に応じて適切なデータベースを選択することが重要です。
ここでは、代表的な4つのデータベースについて解説します。
階層型
階層型データベースは、データが親子関係でツリー構造に編成されたデータベースです。親レコードと子レコードの関係でデータが格納され、ツリー構造で表現されます。
階層型データベースは、組織の階層や製品カタログなど、階層的なデータの管理に適しています。データの構造がシンプルでわかりやすく、管理しやすい、データのアクセスが高速といった特徴があります。
しかし、データの関係が複雑になると扱いが難しくなることがあります。階層型データベースは複雑なデータモデルには適さない点は押さえておくとよいでしょう。
ネットワーク型
ネットワーク型データベースは、階層型データベースを拡張したもので、データがネットワーク構造で編成されたデータベースです。親子関係に加えて、兄弟関係や複数親の関係を持つことができます。
ネットワーク型データベースは、複数の部署の所属する社員がいる場合の社員情報管理システムなど、複雑なデータモデルにも対応可能な点が特徴です。
このように、ネットワーク型は、複雑なデータの関係を管理するのに適していますが、データの追加や削除が複雑になることがあります。
リレーショナル型(関係型)
リレーショナル型データベースは、データがテーブルとテーブルの関係で編成されたデータベースです。
データは、テーブルと呼ばれる二次元表に格納され、テーブル間の関係はキーと呼ばれる共通の項目によって定義されます。また、SQL(Structured Query Language)を使用してデータの操作を行います。
リレーショナル型データベースはデータの正規化とクエリの効率化が容易なため、多くのアプリケーションで広く使用されています。
NoSQL
NoSQLデータベースは、リレーショナル型データベースとは異なるデータモデルを採用したデータベースです。キーバリュー型、ドキュメント型、グラフ型など、様々なデータモデルが存在します。
従来の関係データベースとは異なり、柔軟なデータモデルを採用しており、大量のデータ処理に適しています。構造化されたデータだけでなく、非構造化データの管理にも活用されています。
NoSQLデータベースは、スケーラビリティとパフォーマンスに優れており、大量のデータや高トラフィックなアプリケーションに適してるため、ソーシャルメディア、eコマースサイトなどで使用されている点が特徴です。
データベース設計をする上で大事なポイント

データベースを設計する際の基本的なポイントをいくつか紹介します。
構築するシステムの要件・仕様を理解しているか
データベース設計を始める前に、まず構築するシステムの要件定義を正確に行う必要があります。業務上必要なデータ項目や、システムで実現したい機能をできるだけ具体的に洗い出しましょう。要件定義が甘いと、後から要件変更が発生するリスクが高まります。
要件定義では、データ項目や処理ロジックのみならず、パフォーマンス要件やセキュリティ要件といった非機能要件についても定義が必要です。想定し得る非機能要件を、できる限り具体的にしておくことが大切です。
加えて、ユーザー数やデータ量の将来予測も重要なポイントです。設計段階で処理性能やデータ容量に余裕を持たせることが、将来のシステム拡張に不可欠となります。要件定義時点で認識していなかったことが、後から問題化するリスクを回避するには、余計に時間をかけて要件を洗い出す努力が必要不可欠です。
正規化されているかどうか
データベース設計を行う上で、とても大切なポイントが「正規化」です。正規化とは、データの重複や矛盾をなくし、整合性を高める作業です。
正規化することによるメリットは以下のとおりです。
- データの更新・削除が容易になる: データが重複して存在しないため、一箇所で更新・削除すれば、他の箇所にも反映されます
- データの整合性が保たれる: データの重複がなくなるため、データの矛盾が発生するリスクが軽減されます
- データの容量が削減される: データの冗長性を減らすことで、データベースの容量を削減できます
- クエリの効率化:正規化されたデータベースは、クエリがより効率的に実行されるため、パフォーマンスが向上します
- データの依存関係を明確化:データ間の依存関係が明確になるため、データの構造が理解しやすくなります
正規化には、大きく分けて3つの段階があります。第一正規形は列に対する正規化、第二正規形は列と行の正規化、第三正規形は主キーと非主キー間の依存関係の正規化です。
一般的には、「第三正規形まで正規化を行う」とされており、これによって整合性を保ったデータベース設計が可能となります。ただし、正規化を行いすぎると、アクセス効率が悪化するデメリットもあることに注意が必要です。過度な正規化を防ぎつつ、適切な粒度でテーブル設計を行う感覚が求められます。
将来性の考慮
データベース設計では、将来的なシステムの拡張や変更要件にも柔軟に対応できるよう、余裕を持った設計をすることが大切です。
あるいは業務変更に対応できるように、業務ロジックをテーブル設計にできるだけ依存させないことも重要なポイントといえます。こうした将来性への配慮が、マシンスペックをあげて対処するよりもコストパフォーマンスに優れていると言えます。
具体的には、テーブルの分割やパーティショニングといった手法を用いて拡張性を高めたり、業務ルールを直接SQLにベタ書きせずに、アプリケーション側で実装することで変更に強い構造を作る等の設計ができます。
このようにして、拡張性と柔軟性を兼ね備えたデータベース設計を行うには、単に現時点の要件に合わせるのではなく、少し先の未来を予測し、総合的な視点での設計能力が不可欠と言えます。システムライフサイクル全体を見通した設計構想が重要です。
データベース設計で覚えておくべき要素

データベース設計を成功させるためには、基本的な概念を理解しておくことが重要です。
データベース設計で覚えておくべき要素は以下の4つです。
- エンティティ
- 属性
- 関係
- 関連の多重度
これらの要素はデータベースの構造を決定し、データの整理や検索の効率化に役立ちます。
以下では、それぞれの要素について詳しく説明します。
エンティティ
エンティティは、データベース内で管理される現実世界の事物や概念を表します。
例えば、社員、顧客、製品などがエンティティに該当します。エンティティはテーブルとして表現され、それぞれのエンティティには固有の識別子(主キー)が必要です。
属性
属性は、エンティティの特性や性質を表します。
例えば、社員エンティティには、名前、住所、電話番号などの属性があります。属性はエンティティ内の列として表現され、各属性に対して適切なデータ型が設定されます。
属性を適切に設計することで、管理対象のデータを矛盾なく表現できます。各エンティティにはどのような特性があるのかを検
関係
複数のエンティティ間にある関連のことを関係と呼びます。
例えば、顧客と注文にはお客様が注文を行うという関係があります。関係は、エンティティ間の外部キーや関連テーブルを使用して表現されます。
データベースでは、エンティティ同士が様々な関係を持ちます。各エンティティの関係を正しく定義することが、データベースの設計で重要になります。
関連の多重度
関連の多重度とは、2つのエンティティ間の関係性の数を表すものです。
例えば、1対多、1対1、多対多などの関係があります。1対多は顧客と注文など一方のエンティティがもう一方のエンティティと複数関連できる場合を表します。また、1対1は従業員と社員証など、一方のエンティティがもう一方のエンティティと1つずつしか関連しない場合を表し、多対多は学生と科目など両方のエンティティが複数関連できる場合を表します。
関連の多重度を正しく設定することで、データの整合性を保ち、クエリの効率の向上に繋がります。
データベースの設計手順と流れ
データベースを設計する標準的な手順を解説します。
概念設計
データベース設計の最初のステップは概念設計です。
概念設計は、データベースの基盤を構築するための重要なプロセスであり、システムの全体像を把握し、必要なデータの構造を定義します。
概念設計で行うことは以下のとおりです。
データベースの目的・要件を決める
データベース設計に入る前に、まずはそのデータベースが何のために必要とされているのかを明確にする必要があります。
扱うデータの種類や量、利用シーンやユーザーなど、データベースの目的と要件を洗い出します。
必要な情報を整理しエンティティを抽出
次に、システムで管理する必要がある情報を整理し、それを基にエンティティ(テーブル)を抽出します。
例えば、社員管理システムであれば、社員、部署、役職などがエンティティに該当します。
ER図(Entity Relationship Diagram)を作成
エンティティとそれらの間の関係を視覚的に表現するために、ER図を作成します。
ER図は、データベースの全体構造を視覚化し、エンティティ間の関係や属性を明確にするのに役立ちます。
論理設計(正規化を実施)
概念設計を経て、データベースの基本的な構造とエンティティ間の関係が明確になったら、論理設計を行います。
論理設計では、概念設計で定義されたエンティティや属性を元に、データの整合性や効率性を高めるための詳細な設計を行います。具体的には、データの冗長性を排除し、データの一貫性を保つために正規化を実施します。
正規化は、データの重複を排除し、各テーブル間の関係を最適化するプロセスです。これにより、データの整合性を保ちつつ、効率的なデータベース運用が可能になります。
論理設計で決める内容はデータベースのパフォーマンスと信頼性向上に繋がります。この段階でしっかりと設計を行うことで、後の物理設計や運用段階でのトラブル防止につながると覚えておきましょう。
物理設計
論理設計でデータの構造や正規化を完了した後は、物理設計の段階に進みます。
物理設計では、実際のデータベースシステム上で効率的にデータを格納し、操作するための詳細な設計を行います。このプロセスでは、パフォーマンスや可用性、保守性を考慮しながら、物理的なデータストレージの構成やインデックスの設計などを行います。
以下では物理設計で行う内容を説明します。
性能要件の確認
論理設計で決まったデータベース仕様に対し、必要なレスポンス時間などの性能要件を確認します。
性能要件を適切に設定しないと、運用時に想定外の負荷がかかり、パフォーマンスが低下する可能性があります。そのため、扱うデータ量やアクセス頻度、同時接続ユーザー数などを十分に見積もり、システム全体で要求される性能水準を満たせるよう、データベースの性能要件を決定する必要があります。
大規模なシステムになるほど、性能要件の確認は重要になると覚えておきましょう。
インデックス作成
検索性能を高めるためのインデックスの設計を行います。
インデックスとは、データベース内のデータを効率的に検索するための補助的な構造です。インデックスを適切に作成することで、検索の高速化が図れます。
一方で、インデックスを過剰に作りすぎると、データの挿入・更新・削除の処理が重くなるなどの別の問題が発生します。
そのため、よく検索されるであろうカラムを選び、冗長性にも気をつけながら、検索性能とデータ操作の両立を図れるようインデックスを設計する必要があります。
データ格納領域の決定
データベースに求められる可用性や拡張性から、適切なデータの格納領域を決定します。これは、データベースファイルの配置やパーティショニング、ストレージの選択などが含まれます。
障害に強く、ビッグデータの処理も可能なストレージを採用することで、安定した運用とスケーラブルなデータベースを実現できます。ストレージの特性を十分理解した上で、コストと必要性のバランスを考慮してストレージを決定します。
また、データの重要度に応じて、ストレージの冗長化や暗号化なども検討する必要がある点も押さえておきましょう。
初心者におすすめなデータベース設計ツール
![]()
ここでは初心者がデータベースの設計をするときに便利なツールを紹介します。
GitMind

GitMindは、オンラインでマインドマップやフローチャートの作成ができるツールです。ブレインストーミングやアイディアの整理・共有に威力を発揮します。インターフェースがシンプルで、直感的な操作ができる点が特徴です。
具体的な機能は以下のとおりです。
- マインドマップ
- 組織図やUML
- スイムレーン図
このようにGitMindはさまざまな図表の作成に対応しています。複数人での同時編集も可能で、アイデアの共有やコラボレーションに最適です。
海外のレビューサイトでは高評価を得ており、フリーツールの中でもトップクラスの人気を誇っています。操作性、拡張性、コストパフォーマンスの高さが評価されています。非常に使いやすく生産性の高いツールという印象です。
Lucidachart

Lucidachartは、オンラインで直感的な操作性でフローチャートやネットワーク図、ER図等を作成できるクラウドベースのダイアグラム作成ツールです。
主な特徴としては、
- インターフェースがシンプルで使いやすい
- テンプレートや豊富な図形を利用できる
- ブレインストーミングにも適している
- リアルタイム共同編集が可能
- データのインポート・リンク機能あり
- 外部サービスとの連携が豊富
などが挙げられます。多彩なテンプレートと直感的なUI、共同編集を活かしたコラボレーション機能が高く評価されています。
文書管理や図の共有といった、業務全般において活用できる汎用性の高いツールです。クラウド型グループウェアとして、あるいは単体のダイアグラム作成ツールとしての需要が高まっています。
Draw.io

Draw.ioは、オープンソースのオンラインダイアグラムエディターです。
主な特徴は以下の通りです。
- ストレージ選択が自由(Googleドライブ等)
- デスクトップアプリもあり、オフライン作図可能
- 共同編集に対応
- 機能が豊富
- さまざまなサービスとの連携
- 使い方が直感的でシンプル
Google WorkspaceやMicrosoft 365、Jira、GitHub、GitLabなど、多彩なツールとの親和性が高く、図を活用したコラボレーションに最適です。
オープンソースであることから、自社環境への実装もしやすいのが特長です。優れた拡張性と堅牢なセキュリティが支持されています。
Gliffy

Gliffyは、オンラインのダイアグラム作成ツールです。ConfluenceやJiraとの連携が大きな特徴で、これらのアプリケーション上で直感的な操作性で図を描くことができます。
Gliffyが提供する主な機能・特長は以下の通りです。
- 多数のテンプレートを利用可能
- 日本語UI
- 出力フォーマットが豊富
- バージョン管理機能
- HTML5に対応
- Confluence/Jiraとの連携が強力
ConfluenceやJira利用者が、図を扱う際の定番ツールとして高いシェアを誇っています。
操作性や視認性の高さに加え、Atlassianエコシステムとの親和性の高さが評価されているツールです。
Visual Paradigm

Visual Paradigmは、プロジェクト管理やモデリング、ダイアグラム作成等、開発業務を包括的に支援するツールです。
主な特徴は以下の通りです。
- プロジェクト管理ツールが充実(アジャイル、スクラム等)
- エンタープライズアーキテクチャに対応
- データベースから、コードまで一貫した開発を可能に
- オンラインのダイアグラムエディターも提供
- チームでの同時作業に対応
- 機能が非常に豊富
モデリングからドキュメント作成、プロジェクト管理、チームコラボレーションまで、開発プロセス全体を網羅したオールインワンの統合開発環境が最大の魅力です。
分析や要件定義から設計、実装、テストと受け渡しをスムーズに行えることが高く評価されています。
データベース設計が学べる初心者におすすめ書籍3選

初心者がデータベース設計を学ぶときは書籍を利用するのもおすすめです。
ここでは、データベース設計を学びたい初心者におすすめの書籍を3冊紹介します。
それぞれの書籍の特徴と値段についても説明しますので、ぜひ参考にしてください。
はじめてのデータベース設計: 概念設計 E-R図作成編

『はじめてのデータベース設計 概念設計・ER図作成編』は、データベース設計の基本から応用までをカバーしています。
この本は、特に概念設計やER図の作成に重点を置いており、わかりやすい図解と具体的な例を用いて解説しています。
初心者にとって理解しやすく、実際の業務にも直結する知識が得られる内容です。
シリーズ化しており「データベース設計準備編」「論理設計正規化編」もあるので、あわせてチェックしてみてください。
価格は500円です。
図解まるわかり データベースのしくみ

初心者向けに書かれた『図解まるわかり データベースのしくみ』は、専門用語を極力避け、わかりやすい言葉で解説しています。
価格は1,848円です。
データベース設計だけでなく、SQLの基礎についても触れており、総合的な知識が身につきます。
データベースの基礎知識を身に着けたい人におすすめの一冊になります。
達人に学ぶDB設計徹底指南書: 初級者で終わりたくないあなたへ

『達人に学ぶDB設計 徹底指南書 初級者で終わりたくないあなたへ』は、データベース設計の基本から応用までを徹底的に解説した一冊です。価格は2,860円です。
実務経験豊富な著者が具体的な事例を交えながら、データベース設計のポイントをわかりやすく説明しています。正規化やER図の作成方法だけでなく、実際のプロジェクトで直面する問題への対処法も学べます。
初心者から中級者へのステップアップを目指す方におすすめです。
データベース設計を外注する時のメリット・デメリット

ここではデータベース設計を外注するメリットとデメリットを紹介します。
メリット
データベースの設計を、外部の会社に外注する場合には以下のようなメリットがあります。
| メリット | 内容 |
| 専門知識がある | 外注先にデータベース設計の専門家が在籍しており、高度なスキルを提供可能 |
| 作業効率が高い | データベース専任メンバーが作業に集中できる/ノウハウの蓄積もある |
| 最新技術への対応 | 外注先のほうが最新技術動向を敏感にキャッチしやすい |
| リスク分散 | 要件の共有責任があるためリスクが分散される |
それぞれについて説明します。
データベース設計の専門知識がある
外注先の会社では、データベース設計を専門に行うエンジニアが在籍していることが多いため、高度な知識と経験があるのが大きなメリットです。自社だと、そうした人材の獲得が難しい場合も多いでしょう。
具体的には、業務要件からテーブル定義やデータモデリングまで、データベース設計全般の一連のプロセスを熟知しています。正規化やパフォーマンスチューニングなど、幅広い知識を有しているのが外注先の強みです。
加えて業務分析力やモデリング力も磨かれていることから、要件定義の段階から関与が可能です。自社では気づきにくい課題やリスクも洗い出しやすいでしょう。
このように、外注先はデータベース設計のプロフェッショナル集団であるという特徴があり、自社では補うことが難しい高度なスキルを提供してくれます。これは大きなメリットといえます。
作業効率化
外注先は、データベース業務に専念できるため、作業効率が高まります。自社で同様の作業を行うよりも、期間を短縮できる可能性があります。
外注先では、データベース設計の専任メンバーが存在して専念できる一方で、自社では本業との兼務を強いられがちです。本業との両立に時間が取られ、作業スピードが遅れがちな状況です。
加えて、外注先は反復しがちな定型業務のノウハウやドキュメントテンプレートを蓄積していることも、作業効率の差につながります。自社では、そうしたノウハウ体系の構築に多大な労力が必要となりがちです。
このように、外注先は本業以外の作業に注力できる体制と蓄積ノウハウにより、データベース設計の生産性を大きく引き上げられる特徴があります。
最新技術への対応
外注先の方が最新の技術動向を捉えやすく、最新のデータベースソリューションを提案しやすいという特徴があります。自社では、対応できないような新技術にも柔軟に対応可能です。
外注先は、多数の顧客を抱えていることから、最新技術への要望をいち早くキャッチできるというメリットがあります。新バージョンのデータベースリリースや、記憶媒体の新製品などを素早く採用していきやすいでしょう。
加えて、自社よりも新技術の情報入手が容易なのも大きなポイントです。業界カンファレンスへの参加や。最新技術者コミュニティとのつながりから得られるインプットを、ソリューションにいち早く反映できるという強みが活かせます。
したがって、自社に比べ最新技術トレンドを敏感にキャッチし導入する柔軟性の高さも、外注先の大きなメリットの1つといえます。常に最適な技術をベースとしたソリューションを期待できるでしょう。
リスク分散
設計上の欠陥が発生した場合、その責任の一部を外注先と分散できるのもメリットの1つです。自社だけでリスクを負うよりも、分散できるという安心感が得られます。
加えて、設計上のシステムトラブルが発生した際にも、外注元・先とで原因特定や影響範囲の分析といった初動対応の作業分担ができます。
外注先には、複数の顧客を抱えていることが多く、似たようなケースへの対処経験も豊富なはずです。こうした協力により、迅速な復旧も期待できるでしょう。
このように、外注形態ではリスクや負担がある程度分散できるという心理的な安心感を得られるのも大きなメリットといえます。
デメリット
データベース設計を外注する場合には以下のようなデメリットもある点に注意が必要です。
| デメリット | 内容と対策 |
| 開発コスト増 | 外注費用の割高感 -> 複数社からの見積比較、フェーズ分割発注 |
| 要件漏れリスク | 後工程での仕様変更リスク -> 綿密な要件定義とレビューの実施 |
| 設計品質不安 | 品質水準が不明確 -> 信頼性の高い外注先選定、工程管理の徹底 |
| 情報流出リスク | 外注先からの情報漏えい -> 秘密保持契約締結、提供情報制限 |
開発コストが高い
外部委託するため、人件費を含むコストが内製するよりも割高感があります。規模によっては、予算超過する可能性もあります。
このため、事前に複数社の見積もりを取り、コストと納期のバランスを確認する必要があります。場合によっては要件の優先事項を決めて、フェーズごとに分割発注することでコスト増を防ぐこともできます。
加えて、進捗に応じた対価支払方式(出来高払い)を採用することで、働き方改革や生産性向上などの外注メリットを享受しつつ、コスト面のコントロールも可能です。リスクをある程度分散できる契約形態を検討することが、ポイントだと言えます。
要件漏れのリスク
外注先との要件共有が不十分だと、後工程で要件変更や仕様変更が多発します。これを防ぐには、丁寧な要件定義とドキュメント化が重要です。
要件定義時点で、想定外だった要求が後から顕在化するケースも少なくありません。このため、外注先と綿密に要件をすり合わせる作業が欠かせません。ヒアリングやレビューを重ねることで、要件漏れのリスクを下げることができます。
また、要件変更が発生した際の影響範囲分析と見積もり改定のプロセスを、契約時点で定めておくことも重要です。作業範囲の変更に応じた追加コストと、工数が明確になるようにしておくことで、予算超過といったリスクを回避することが期待できます。
品質不安
信頼できる実績のある外注先を選定することで、このリスクはある程度回避できます。
実績や信頼性を確認するため、事前に外注先の評価軸を設定します。過去の類似案件の成果物確認や、保有人材のスキルレベル確認、業界での評価調査などを行うことが重要です。
加えて定期的な設計レビューを実施し、自社側で品質管理を行うことで、最終成果物の完成度をある程度コントロール可能です。
このように、外注先評価と綿密な工程管理を行うことで、最低限の品質水準を担保することが可能となり、設計品質への不安感は相対的に低減できるはずです。
自社ノウハウ流出
秘密保持契約の締結を徹底し、提供する情報範囲についても配慮することが求められます。
具体的には、秘密保持条項・守秘義務条項を含む請負契約を取り交わします。これは、法的拘束力がある契約であるため、外注先の情報管理はある程度担保されるといえます。
加えて、外注先へ提供する具体的データについても、業務遂行に必要最小限の範囲にとどめる等の配慮が必要です。例えば、個人情報データは可能な限り加工や削除を行った上で提供する、などの対応が考えられます。
このように、秘密保持契約の締結と提供情報の管理を徹底することで、自社情報の外部流出というリスクを防止するための一定のハードルは確保できるものと考えます。
自社内設計のメリット・デメリット
![]()
ここではデータベースの設計を自社内で行う場合のメリットとデメリットを紹介します。
メリット
データベースの設計を自社内で行う場合には以下のようなメリットがあります。
| メリット | 内容 |
| 開発コストが低い | 外注費用不要で済む/人材育成への投資に |
| 要件把握しやすい | 社内での密なコミュニケーションが可能 |
| 社内事情に特化 | 自社の運用環境に対応した設計ができる |
| 自社ノウハウの蓄積 | 設計能力を社内に蓄えられる |
開発コストが低い
外注費用が不要な分、人件費以外のコストを抑えられるのが大きなメリットです。自社内リソースのみで設計できるため、コスト面で有利になります。
仮に、社内に適任者がいなければ教育コストが別途かかる可能性もありますが、中長期的には人材育成という意味で投資となります。外注と比べて、トータルのコスト削減に寄与します。
加えて、データベース設計スキルを身につけた社員が、他の業務分野でも活躍できる可能性が広がります。例えば、システム開発部門への異動やデータ分析業務での活用などが考えられ、人材の再活用面でもメリットがあるといえます。
要件把握しやすい
社内でのヒアリングや仕様確認が行いやすいため、要件を正確に理解しやすいというメリットがあります。社内メンバー間で、密にコミュニケーションをとれる環境にあることがポイントです。
加えて、社内設計メンバーは基幹業務システムの仕組みや業務用語などある程度理解していることが多く、要件定義に理解のギャップが出にくいという特徴もあります。
このように、自社内での設計は、業務内容の理解や要件定義を行いやすいという点で大きなメリットがあると言えます。
社内事情に特化
自社の業務形態や運用環境を反映した設計ができるのも、大きなメリットです。社内事情に合致したデータベース設計が可能です。
例えば、社内で使用している既存システムとのデータ連携方法を考慮した設計ができたり、自社向けに特化した業務ロジックを組み込みやすかったりします。
加えて、社内のITリテラシー状況を踏まえ、運用しやすいUI設計での実装要望に対応しやすいといったメリットもあります。
このように、自社の文化や技術力に特化した最適なデータベース設計ができることが、社内設計の大きなアドバンテージといえます。
自社ノウハウの蓄積
設計のノウハウやアウトプットを社内に蓄積していけるのも魅力の1つです。次回以降の設計業務がしやすくなります。
加えて、例外事象への対応経験も共有資産として社内に蓄積されていきます。これは、外注先からは得られない自社のユニークな財産となります。
さらに、データベース設計を社内で構築することによる、モチベーション向上という効果も大きな収穫だと考えます。 技術力向上への前向きな姿勢や、意識改革が期待できるでしょう。
デメリット
自社内でのデータベース設計には、以下のようなデメリットも存在します。
| デメリット | 内容 |
| 専門知識の不足 | 高度な設計スキルを社内で準備する難易度が高い |
| 作業効率の低下 | 本業との兼業や人材不足による効率低下が生じやすい |
| 最新技術への対応遅れ | 自社内では技術トレンドを常に把握しづらい |
| リスクの集中 | 設計ミスの責任が自社内に閉じてしまう |
データベース設計の専門的知識が社内にない
高度なデータベース設計のノウハウを、社内に保有していないリスクがあります。外注先のような、専門性に欠ける可能性が高いです。
具体的には、論理データモデリングやテーブル定義、SQL設計といった、設計技法が不十分な場合が多いでしょう。最適なデータ構造の設計に必要なスキル習得に、多大な労力と時間がかかります。
また、大規模システム構築経験不足から、パフォーマンス面でのチューニング手法や大量データへの拡張性確保といったノウハウも不足しがちです。
以上のように、自社内に適切なスキルセットを有するデータベース設計人材を揃えることの難易度が高いという側面があると言えます。
作業効率低下
本業との両立や人材不足等により、作業スピードが上がらない懸念があります。業務量に応じた、適正人員の確保が難しいでしょう。
自社内にデータベース業務の専任体制を整えずに、兼業で対応せざるを得ない場合、本業との両立に苦慮することになります。残業が増える、本業成果の低下を招く、といった懸念が生じやすいでしょう。
加えて、過度な業務集中を避けるために複数名での担当割り当てが必要ですが、データベース設計人材の取り合いとなり、プロジェクト全体の作業効率が低下することも予想されます。
過去の類似案件経験や、ドキュメントテンプレートの共有化不足も作業効率の障害となりやすい側面です。
最新技術への対応遅れ
自社内だと、最新技術動向への対応が遅れがちです。新バージョンや新技術の採用スピードが、出しにくいリスクがあります。
自社内において、最新技術を常にウォッチし続けるのは難しく、新バージョン情報や技術トレンドを収集・分析する体制を整えることが容易ではありません。
加えて、新技術のPOC(概念実証)を行う時間的余裕もなかなか取れず、リリースからある程度時間が経過してからの採用となりがちです。
結果として、汎用性が高く旬の技術を活用した設計ができず、自社向けに最適化されたデータベース設計を行うことが難しくなるリスクがあるといえます。
リスク集中
設計上の欠陥が発生した場合、その責任が自社内に集中しがちです。リスクを分散することが難しいという側面もあります。
例えば、要件定義の不備や誤解から重大な設計ミスが発生した場合、その責任は自社設計メンバーが全面的に負うことになります。外注先とは違い、リスク分散が難しい状況です。
加えて、信頼性確保のための各種試験や防御的な設計手法への対応が手薄になりがちで、予期せぬエラーや障害の発生頻度が高まる可能性があります。
このように、自社内設計では想定外の事態が発生した際のリスクが、内部に閉じてしまう側面があるという懸念点が存在するといえます。
データベース設計のまとめ

本記事では、データベース設計の基本的な考え方から構築手順とポイントについて解説しました。
要件定義の段階からテーブル設計、試験運用と評価に至る一連の流れの中で、特に重要視すべきポイントは、正規化に基づいたデータ処理の効率性と、将来の拡張性を見越した柔軟な設計を行うことです。
記事の内容で不明な点やご質問がございましたら、株式会社Jiteraまでお気軽にお問い合わせください。システム要件に応じた、最適なデータベース設計と構築を提供させていただきます。



