

予測モデルは、様々な産業において重要な役割を果たしています。ビジネスから医療まで、予測モデルは未来の傾向を予測し、最適な決定を下すための貴重なツールとなっています。
この記事では、予測モデルの概要、その種類、そして具体的な実装方法について詳しく解説します。予測モデルについての理解を深めたい方は、ぜひ参考にしてみてください。
東京都在住のライターです。わかりづらい内容を簡略化し、読みやすい記事を提供できればと思っています。
予測モデルとは?
予測モデルとは、特定の出来事が起こる可能性を予測するための数式やルールのことを指します。
予測モデルによって、将来起こり得ることを予測することができます。過去のデータをもとに、将来の傾向を予測することができるからです。
ここでは、予測モデルの概要とその重要性についてみていきましょう。
予測モデルの概要
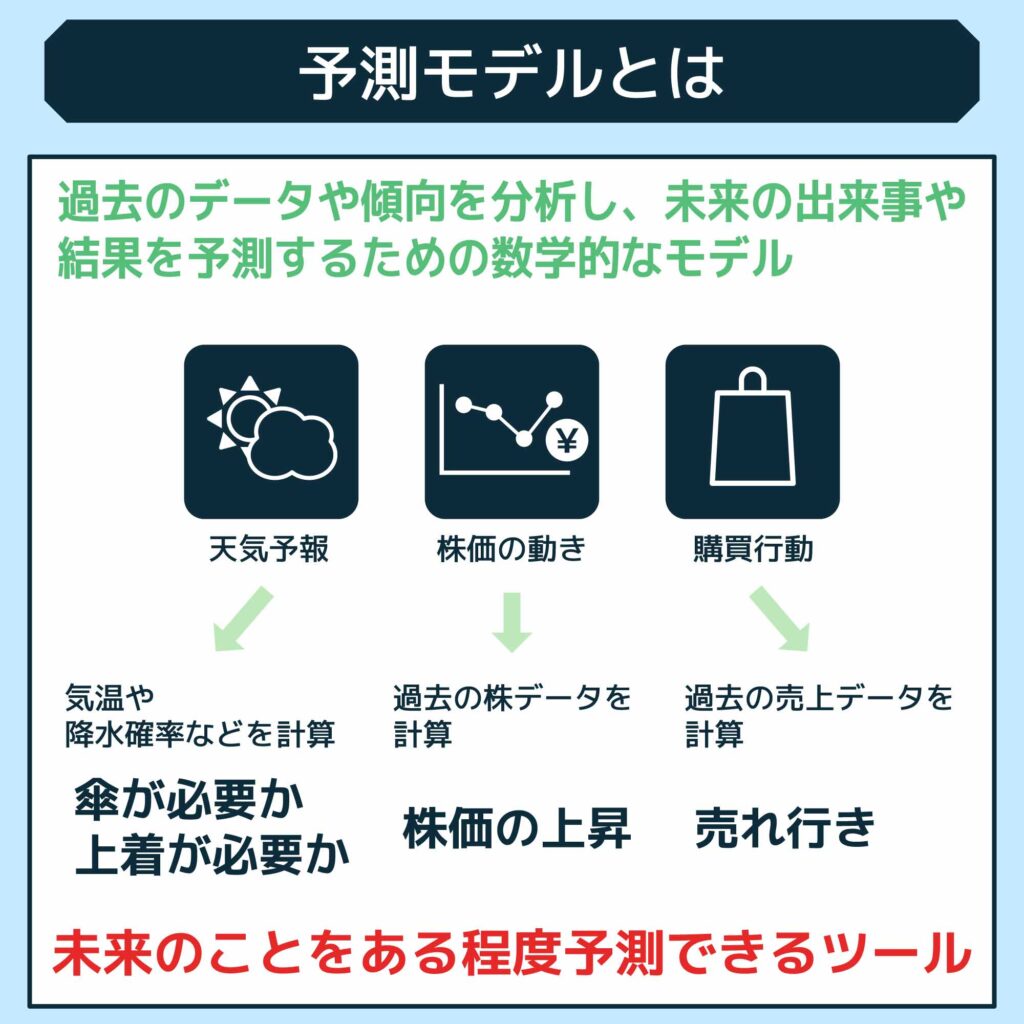
予測モデルは、過去のデータや傾向を分析して、未来の出来事や結果を予測するための数学的なモデルです。このモデルは、気象予報、株価の動き、消費者の購買行動など、さまざまな分野で利用されています。
予測モデルを作るには、大量のデータと、そのデータからパターンを見つけ出すための高度な分析技術が必要です。
正確な予測を行うことで、リスクを管理したり、将来の計画を立てたりする際に役立ちます。
しかし、予測モデルは使用するデータの質や量、選択されたモデルの種類によって、その正確性が大きく変わるため、常に注意が必要なものと位置付けられています。
予測モデルの重要性と応用範囲
予測モデルは、未来のことをある程度予測できるツールであり、さまざまな場面で重宝しています。
たとえば、天気予報では、予測モデルを使って明日の天気を予測します。具体的には、気温や降水確率などを計算して、傘を持っていくべきか、コートが必要かなどを教えてくれます。
そして、予測モデルの応用範囲は天気予報だけに留まりません。ビジネスの世界では、商品の売れ行きや株価の動きを予測するのにも使われています。
また、医療分野では、病気の流行を予測して、必要な準備を整えるのに貢献することもあります。
つまり、予測モデルは様々な場面で私たちの生活をより良くするために使われているのです。
予測モデルの種類

予測モデルにはいくつかの種類があり、それぞれ特定の状況や目的に最適化されています。
予測モデルの種類を理解しなければ、それらを有効に活用することはできません。
ここでは、予測モデルの種類について詳しくみていきましょう。
分類モデルと回帰モデルの違い
| 特徴 | 分類モデル | 回帰モデル |
|---|---|---|
| 目的 | データをカテゴリーに分類する | 数値の予測(連続する数値) |
| 出力の形式 | カテゴリーのラベル(例:「迷惑メール」、「通常のメール」) | 具体的な数値(例:家の価格、明日の気温) |
| 使用例 | メールの分類、画像内のオブジェクトの識別 | 家の価格の予測、明日の気温の予測 |
分類モデルと回帰モデルは、予測モデルの中でも特によく使われる2種類のモデルです。
これらのモデルは、データから未来を予測するという共通の目的を持っていますが、扱う問題の性質や目指す結果において大きな違いがあります。
ここでは、分類モデルと回帰モデルの違いについて、理解しやすいように詳しく解説していきます。
まず、分類モデルは、データを事前に定義されたカテゴリーやクラスに「分類」するためのモデルです。つまり、入力されたデータがどのグループに属するかを予測することが目的です。
たとえば、メールが「迷惑メール」か「通常のメール」かを判断する場合や、ある画像に写っているのが「犬」か「猫」かを識別する場合などが分類モデルが使用できます。
一方、回帰モデルは、数値の予測に特化しています。具体的には、入力されたデータに基づいて、連続する数値(価格や温度など)を予測することが目的です。
たとえば、家の大きさや立地、築年数などからその家の価格を予済する場合や、過去の気温データから明日の気温を予測する場合などに回帰モデルが使用されます。
主な予測モデルの種類と特徴
機械学習では、予測モデルを使って未知のデータから予測を行います。主な予測モデルには、次のようなものがあります。
- 線形回帰モデル
- 決定木モデル
- ランダムフォレストモデル
- ニューラルネットワークモデル
各項目について、詳しく解説します。
線形回帰モデル
線形回帰モデルは、変数間の線形(直線的)な関係をモデリングする最も基本的な予測モデルの1つです。
1つまたは複数の独立変数(予測因子)と1つの従属変数(目的変数)の間の関係を表します。線形回帰は、特にデータのトレンドを理解したい時や、簡単な予測を行いたい時に役立ちます。
決定木モデル
決定木モデルは、データを分類または数値予測するために、決定木と呼ばれる木構造を使用します。
このモデルは、分岐点(ノード)ごとに質問をし、データを段階的に細分化していき、最終的に予済を行います。決定木モデルは、その可視化が容易で理解しやすいという特徴があります。
ランダムフォレストモデル
ランダムフォレストモデルは、複数の決定木を組み合わせた学習モデルです。このモデルは、個々の決定木の予測を集約することで、一般的に高い予測精度を達成します。決定木モデルの過学習を防ぎつつ、モデルの堅牢性を高めることができます。
ニューラルネットワークモデル
ニューラルネットワークモデルは、人間の脳の神経細胞(ニューロン)のネットワークを模倣したモデルで、特に複雑なパターンや非線形の関係を学習するのに適しています。
深層学習の基礎となる学習方法で、画像認識、自然言語処理、複雑な予測タスクなど、幅広い応用が可能です。
予測モデルの作り方

ここでは、予測モデルの作り方について詳しくみていきます。
機械学習アルゴリズムの選択とデータの前処理
機械学習アルゴリズムを選択する際には、データの種類や目的に応じたものを選ぶことが重要です。
データの前処理の方法として、欠損値や外れ値の処理、正規化や標準化などがあります。あるデータセットの欠損値が多い場合、それをそのまま使うとモデルの精度が低下するでしょう。
しかし、それらの数値を平均値や中央値で埋めたり、最頻値で埋めたりすることで解決できます。また、どうしても使えないデータについては、除去することで、活用するデータを質の高いものにさせられます。
また、以下の記事では、AI開発に必要な知識レベルや勉強方法について紹介しています。興味がある方は、ぜひ参考にしてみてください。

モデルの学習と評価方法の選定
まずは、モデルの学習方法を選定します。
具体的には、機械学習やディープラーニングなど、どのような手法を使うかを決めましょう。次に、評価方法を選定します。
たとえば、精度や再現率などの評価指標を決め、それに応じて活用する手法を考えます。そして、予測結果と実際の結果を比較して、誤差を評価します。
そういった評価指標をもとに、モデルの改善を繰り返し行うことで、データの精度がどんどん高まってい区はずです。
また、モデルの学習には、適切なデータセットの選定も重要です。モデルの性能向上には、データの品質や量にも注目しなければなりません。
予測モデルの実装手順

それでは、予測モデルの具体的な実装手順をみていきましょう。主に以下2つの方法で予測モデルを実装できます。
- Python
- Tableau
それぞれ詳しくみていきます。
Pythonを使用した予測モデルの実装方法
Pythonを使用して予測モデルを実装する方法は、機械学習ライブラリを利用することで、比較的簡単に行えます。
ここでは、Pythonで広く使用されている機械学習ライブラリであるscikit-learnを使って、線形回帰モデルとランダムフォレストモデルの実装方法を例に挙げて説明します。
環境準備
まず、必要なライブラリをインストールします。scikit-learnは、多くの機械学習モデルを簡単に扱うことができるライブラリです。以下のコマンドを実行してインストールしてください。
bashCopy code
pip install numpy pandas scikit-learn matplotlib
線形回帰モデルの実装
線形回帰モデルを使用して、あるデータセットから数値を予測する例を見てみましょう。
pythonCopy code
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# データの準備(例として、ランダムなデータを生成)
np.random.seed(0)
X = np.random.rand(100, 1) * 5 # 独立変数(例:家の大きさ)
y = 3 * X + np.random.randn(100, 1) * 2 # 従属変数(例:家の価格)
# データを訓練用とテスト用に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 線形回帰モデルを作成して訓練
model = LinearRegression()
model.fit(X_train, y_train)
# テストデータで予測
predictions = model.predict(X_test)
# 予測結果をプロット
plt.scatter(X_test, y_test, color=’black’, label=’Actual data’)
plt.plot(X_test, predictions, color=’blue’, linewidth=3, label=’Linear regression line’)
plt.xlabel(‘X value’)
plt.ylabel(‘y value’)
plt.title(‘Linear Regression Example’)
plt.legend()
plt.show()
ランダムフォレストモデルの実装
次に、ランダムフォレストモデルを使って、分類問題を解く例を見てみましょう。
pythonCopy code
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# アヤメのデータセットをロード
iris = load_iris()
X = iris.data
y = iris.target
# データを訓練用とテスト用に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# ランダムフォレストモデルを作成して訓練
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# テストデータで予測
predictions = model.predict(X_test)
# 正確度を計算
accuracy = accuracy_score(y_test, predictions)
print(f’Accuracy: {accuracy}’)
こちらは、Pythonの機械学習において、有名な練習問題「アヤメの分類」を参考にしています。詳しくは、こちらの記事に記載されているので、ぜひ参考にしてみてください。
参照:第10回 アヤメの分類
Tableauを使用した予測モデルの構築手順
Tableauは、データの可視化やビジネスインテリジェンスに広く使われているツールですが、簡単な予測モデルの構築も可能です。Tableauを使った予測モデルの構築手順を説明します。
ステップ 1: Tableauの準備
まず、Tableau Desktopがインストールされていることを確認します。Tableau Publicでも基本的な予測機能は使用できますが、より高度な分析機能を利用するにはTableau Desktopが必要です。
ステップ 2: データの接続
Tableauを開き、「データの接続」を選択して、分析したいデータソースに接続します。Tableauは様々なデータソースに対応していますので、必要に応じてファイルやデータベースを選択します。
ステップ 3: 分析の準備
データソースに接続したら、分析に必要なフィールドを選択して、ビジュアライゼーションを作成します。予測を行いたい変数を軸に設定し、分析の基礎となるビューを作ります。
ステップ 4: 予測の追加
作成したビューに対して、予測を追加します。これを行うには、以下の手順を実行します。
- 「分析」パネルを開きます。
- 「トレンドライン」または「モデル」セクションを探します。
- 「予測」をビューにドラッグします。
Tableauは自動的にデータを分析し、線形回帰などの方法を用いて予測モデルを構築します。この予測は、ビュー上に表示され、未来のトレンドやパターンを視覚的に把握することができます。
ステップ 5: 予測のカスタマイズと評価
予測がビューに追加されたら、その精度や期間などをカスタマイズすることができます。「分析」→「予済オプション」から、予測期間の長さや信頼区間など、さまざまな設定を調整できます。
また、Tableauの予測モデルは簡単に構築できますが、モデルの精度や適切性を確認することが重要です。実際のデータと予測結果を比較し、予測モデルがビジネスニーズに合致しているか検証してください。
ステップ 6: ダッシュボードの共有
予測モデルの構築が完了したら、その結果をダッシュボードに組み込み、関係者と共有することができます。Tableau ServerやTableau Onlineを使用して、ダッシュボードをウェブ上で公開し、意思決定プロセスを支援します。
Tableauを使用した予測モデルの構築は、直感的な操作と強力なビジュアライゼーション機能により、データからの洞察を迅速に得ることができます。ただし、より複雑なデータ分析やモデルのカスタマイズが必要な場合は、PythonやRなどのプログラミング言語を使用した分析が適している場合もあります。
詳しくは、こちらの記事で解説されているので、ぜひ参考にしてみてください。
参照:予測モデリング
予測モデルの応用事例と展望

近年では、機械学習や人工知能の進化により、より複雑なデータセットからも精度高い予測を行えるようになりました。この進化に伴い、予測モデルは新たな領域への応用や、既存の問題へのより洗練された解法を提供する展望を開いています。
昨今は、医療から金融、エネルギー、交通、小売りに至るまで、予測モデルの応用範囲は広がり続けています。
ここでは、予測モデルの応用事例について詳しく見ていきます。
予測モデルの実際のビジネス応用例
予測モデルはビジネスの様々な側面でその価値を示しており、効率性の向上、コスト削減、収益の増大といった成果を実現しています。
小売業では、予測モデルが顧客行動の分析や商品の需要予測に利用され、サプライチェーンの最適化や顧客に最適化されたマーケティング戦略の立案に寄与しています。商品の在庫管理の最適化から、顧客ごとにカスタマイズされた広告の提供まで、小売業者は顧客満足度の向上と効率的な在庫管理を実現可能です。
金融業界では、信用スコアモデルがローンの承認プロセスの自動化に活用され、市場トレンドの予測やリスク管理にも予測モデルが重要な役割を果たしています。金融市場のデータ分析により、投資戦略の策定や価格変動リスクの評価が行われています。
製造業界では、予測モデルが需要予測や生産プロセスの最適化に用いられています。機械学習を活用した予測保全により、製造ラインのダウンタイムを最小限に抑えることが可能です。また、製品の品質管理にも予測モデルが使われ、製造過程での不良品発生を未然に防ぐ効果があります。
予測モデルの将来の可能性と課題
予測モデルは、上述したように、事前にリスクを見極めたり、未来のトレンドを掴むことができるため、さまざまな分野で活用されています。
しかし、予測モデルには課題もあります。1つは、データの質と量に大きく依存することです。予測の正確性を高めるには、大量で正確なデータが必要ですが、常にこれを確保することは容易ではありません。また、予測モデルは過去のデータに基づいて未来を予測するため、突発的な事象や大きく社会が変化するような出来事に対しては対応が難しいという問題があります。
また、予測モデルの高度化に伴い、その仕組みを理解し、適切に操作するためには専門的な知識が必要になります。これが、一般の人々や小規模な企業が予測モデルを活用する際の障壁となることがあります。
つまり、予測モデルはその可能性を最大限に引き出すためには、データの質の向上、モデルの透明性の確保、そして人々がそれを理解し活用できるような支援体制の整備が必要だということです。
これらの課題に対処することで、予測モデルのさらなる発展と応用が期待できるでしょう。
予測モデルのまとめ

この記事では、予測モデルの種類、作り方、実装手順、応用事例と展望について詳しく解説しました。
予測モデルは、様々なビジネス分野における意思決定を支援し、効率性や精度を向上させる役割を果たします。
機械学習やAIの進化により、予測モデルの可能性は日々広がっています。しかし、その活用にはデータの質と量、予測モデルの透明性、そして人々が予測モデルを理解し活用できる環境づくりが求められます。
これらの課題を克服し、予測モデルの可能性を最大限に引き出すことで、さらなるビジネスの成長と社会の発展が期待できるでしょう。今回の内容も参考に、予測モデルについての理解を深めてみてはいかがでしょうか。
また、Jiteraでは、要件定義を書くだけでAIが生成するツールで、アプリ・システム開発を行っています。制作している途中で要件が変更になっても柔軟に修正しながら開発できるので、アプリ開発・システム開発のご相談があればお気軽に相談ください。



