

人工知能技術の進化が加速する中、注目を集めているのが小規模言語モデル(SLM)です。その代表格として、Microsoftが開発した「Phi-3-mini」が話題を呼んでいます。
大規模言語モデルとは異なるアプローチで高い性能を実現し、効率的なリソース利用やオープンソースという特性により、AIの民主化に大きく貢献すると期待されています。
本記事では、Phi-3-miniの特徴や使い方、そして従来のモデルとの比較を通じて、その可能性を探ります。
20年超のシステム開発経験を活かし、AI・機械学習のエバンジェリストとして活動中。新技術の追求と、日本のAI活用を世界一に導くことに情熱を注ぐ。開発の全工程に精通し、知識と行動力で未来を切り拓く。
Phi-3-miniとは

Phi-3-miniは、Microsoftが開発した小規模言語モデル(Small Language Model: SLM)の一つです。大規模言語モデル(Large Language Model: LLM)とは異なり、比較的小さなパラメータ数で高い性能を実現しています。
Phi-3-miniの主な特徴は以下の通りです:
- モデルサイズ:約15億パラメータ
- 開発元:Microsoft Research
- ライセンス:MIT License(オープンソース)
- 用途:テキスト生成、コード生成、質問応答など
Microsoftは、Phi-3-miniを通じて、小規模でありながら高性能な言語モデルの可能性を示し、AI技術の民主化を目指しています。このモデルは、研究者やデベロッパーが容易に利用でき、様々な応用分野での活用が期待されています。
Phi-3-miniの特徴

Phi-3-miniは、小規模ながら高い性能を持つ言語モデルとして注目を集めています。以下では、Phi-3-miniを導入することで得られる主なメリットについて解説します。
小規模言語モデル(SLM)を採用
Phi-3-miniは、MITライセンスの下でオープンソースとして公開されており、研究や商用利用を含む自由な利用と改変が可能です。
世界中の開発者がモデルの改善に貢献でき、その構造や学習プロセスの透明性も確保されています。さらに、ローカル環境にダウンロードして使用できるため、オフライン環境でも利用可能で、セキュリティやプライバシーに配慮が必要な場面でも安心して使用できます。
これらの特徴により、Phi-3-miniは幅広い用途での活用が期待されています。
高い処理速度と精度
Phi-3-miniは、小規模ながら高い処理速度と精度を実現しています。これは、効率的なモデル設計、最適化されたアルゴリズム、タスク特化型学習という三つの要因によるものです。
最新の自然言語処理技術を活用し、少ないパラメータ数で高性能を発揮するよう設計されており、推論時の計算効率を高めるアルゴリズムにより応答速度が向上しています。
また、特定のタスクに焦点を当てた学習により、そのタスクにおいて高い精度を実現しています。
これらの特徴により、Phi-3-miniは大規模モデルに匹敵する性能を、より少ないリソースで提供することが可能となっています。
効率的なトレーニング手法による学習
Phi-3-miniの開発では、効率的なトレーニング手法が採用されています。
具体的には、質の高いデータセットを重視したトレーニング、特定のタスクに特化したタスク指向学習、そして転移学習の活用が特徴として挙げられます。大量のデータではなく、厳選されたデータを使用し、特定のタスクに焦点を当てた学習を行うことで、効率的に性能を向上させています。
また、事前学習済みモデルを基に特定のタスクにファインチューニングすることで、新しいタスクへの適応を効率的に行っています。
これらの手法により、Phi-3-miniは限られたリソースで効果的な学習を実現し、高い性能を獲得しています。
オープンソースモデル
Phi-3-miniは、オープンソースモデルとして公開されており、多くの利点を有しています。
MITライセンスの下で提供されているため、研究や商用利用を含め、自由に利用・改変が可能です。オープンソースの特性を活かし、世界中の開発者がモデルの改善に貢献できる環境が整っています。
また、モデルの構造や学習プロセスが公開されているため、その動作や性能を詳細に検証することができます。さらに、ローカル環境にダウンロードして使用できるため、オフライン環境でも利用可能であり、セキュリティやプライバシーに配慮が必要な場面でも安心して使用できます。
これらの特徴により、Phi-3-miniは幅広い用途での活用が期待されています。
GPT-3.5との比較

Phi-3-miniとGPT-3.5の比較では、いくつかの重要な違いが存在します。
最も顕著な差異はモデルサイズで、Phi-3-miniが約15億パラメータ、GPT-3.5が約1750億パラメータと大きく異なります。この規模の違いは処理速度とリソース要件に影響し、Phi-3-miniはより高速で、一般的なPCでも利用可能な軽量モデルとなっています。
機能面では、Phi-3-miniが特定のタスクに特化した性能を持つのに対し、GPT-3.5はより広範囲のタスクに対応できる汎用性を有しています。また、Phi-3-miniはオープンソースモデルであるため、ユーザーが自由にカスタマイズできる点も特徴です。
これらの違いにより、Phi-3-miniは特定の用途や環境において、GPT-3.5よりも適している場合があります。
| 特徴 | Phi-3-mini | GPT-3.5 |
| モデルサイズ | 約15億パラメータ | 約1750億パラメータ |
| 処理速度 | 高速 | 中程度 |
| リソース要件 | 低 | 高 |
| 特化性 | タスク特化型 | 汎用型 |
| カスタマイズ性 | 高(オープンソース) | 限定的 |
| オフライン利用 | 可能 | 困難 |
Phi-3-miniの使い方

Phi-3-miniを実際に使用する方法について、具体的に説明します。以下では、Hugging Faceを利用する方法を例に挙げて解説を進めます。
必要な環境
Phi-3-miniを使用するには、適切な環境設定が必要です。まず、Python 3.7以上がインストールされていることが前提条件です。また、PyTorch 1.10以上とTransformers 4.20.0以上のライブラリが必要となります。
計算速度を向上させるためには、CUDA対応のGPUを搭載したマシンを推奨しますが、CPUのみの環境でも動作は可能です。メモリについては、最低8GB以上を推奨しますが、より大きなモデルや複雑なタスクを扱う場合は16GB以上が望ましいでしょう。
オペレーティングシステムは、Windows、MacOS、Linuxのいずれでも問題ありません。
2種類の利用方法
Phi-3-miniを利用する方法には、主に2つのアプローチがあります。
1つ目はMicrosoft Azureを利用する方法で、クラウド環境でモデルを簡単に展開できます。
2つ目はHugging Faceを利用する方法です。Hugging Faceは、多くの事前学習済みモデルを提供するプラットフォームで、Phi-3-miniもここで公開されています。
ここでは、Hugging Faceを利用する方法を例に挙げて解説を進めます。この方法では、Pythonスクリプトを使用してローカル環境でモデルを直接操作できるため、よりカスタマイズ性が高く、細かな制御が可能です。
Phi-3-miniのインストール
Phi-3-miniのインストールは、Hugging Faceのtransformersライブラリを使用します。
「pip install torch transformers」でライブラリをインストールし、Pythonスクリプトで必要なモジュールをインポートします。
「model_name = “microsoft/phi-3-mini”」を設定し、AutoModelForCausalLMとAutoTokenizerでモデルとトークナイザーをロードします。
これにより、Phi-3-miniのモデルがローカル環境にダウンロードされ、使用準備が整います。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# モデル名の指定
model_name = “microsoft/phi-3-mini”
# モデルとトークナイザーのロード
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
モデルのロード
Phi-3-miniモデルのロードでは、効率的な計算のためGPUの利用が推奨されます。
PyTorchをインポートし、「device = “cuda” if torch.cuda.is_available() else “cpu”」で利用可能なデバイスを自動選択します。
「model = model.to(device)」でモデルを指定デバイスに移動させ、GPUかCPUでの計算を可能にします。
GPUを使用すると計算速度が向上しますが、CPUでも動作可能です。これらの手順でモデルのロードが完了し、Phi-3-miniの使用準備が整います。
# 利用可能なデバイスの自動選択
device = “cuda” if torch.cuda.is_available() else “cpu”
print(f”Using device: {device}”)
# モデル名の指定
model_name = “microsoft/phi-3-mini”
# モデルとトークナイザーのロード
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# モデルを指定デバイスに移動
model = model.to(device)
基本操作
Phi-3-miniの基本操作は、主にテキスト生成を行います。
まず、入力テキスト(プロンプト)を定義し、トークナイザーでエンコードします。
次に、エンコードされた入力をモデルに渡してテキスト生成を行います。生成時にはテキストの最大長などのパラメータを指定できます。
最後に、生成されたテキストをデコードして人間が読める形式に変換し、結果を表示します。これらの基本操作を組み合わせることで、様々なタスクにPhi-3-miniを活用できます。
# モデルの使用例
input_text = “完璧なピザの作り方を教えてください。”
input_ids = tokenizer.encode(input_text, return_tensors=”pt”).to(device)
# 推論の実行
with torch.no_grad():
output = model.generate(input_ids, max_length=200, num_return_sequences=1)
# 結果のデコード
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
Phi-3-miniの回答例

Phi-3-miniの能力を示すいくつかの回答例を紹介します。
プログラムコードの生成
要件:「Pythonで、1から100までの偶数の和を計算するプログラムを作成してください。」
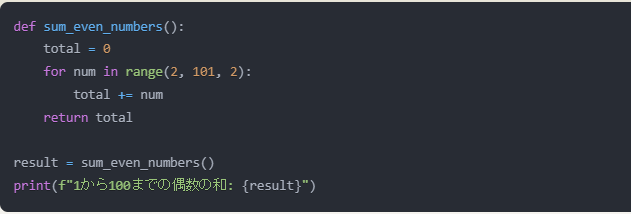
文章の生成
設定:「宇宙を舞台にしたSF小説の冒頭部分を300文字程度で書いてください。」

ビジネス企画の提案
要望:「環境に配慮したサステナブルな食品パッケージの企画案を提案してください。」

今後Phi-3-miniはどのように発展していく?

Microsoftは、Phi-3-miniの成功を基に、小規模言語モデルの可能性をさらに追求しています。注目すべきは、「Phi-3-Small」(約3.8億パラメータ)と「Phi-3-Medium」(約7.4億パラメータ)という新モデルのリリース予定です。
これらは、Phi-3-miniより大きいながらも小規模言語モデルの範疇に収まります。新モデルの導入により、タスク対応力の向上、精度の改善、多言語対応の強化が期待されます。
また、医療や法律などの特定ドメインに特化したモデルの開発や、スマートフォンやIoTデバイスでのAI活用の加速も見込まれています。
これらの発展により、Phi-3シリーズは小規模言語モデルの新たな可能性を切り開き、AI技術の民主化と幅広い産業への応用を促進することが期待されています。
まとめ:Phi-3-miniは将来的な活用が期待されるSLM

Phi-3-miniは、小規模言語モデル(SLM)の画期的な例として注目を集めています。
高い処理速度と精度、効率的なリソース利用、オープンソースの特性により、幅広い分野での活用が期待されています。GPT-3.5のような大規模モデルと比較しても、特定のタスクでは遜色ない性能を発揮し、低リソース環境での実行やカスタマイズの容易さが強みです。
Phi-3-SmallやPhi-3-Mediumなどの新モデルにより、エッジコンピューティングやIoTデバイス、特定ドメインのAIソリューションなど、多様な用途での活用が見込まれます。
これらの発展はAI技術の民主化を促進し、イノベーションを加速させ、日常生活やビジネスにおけるAIの重要性を高めるでしょう。
AIに関する質問やAIを使ったシステム開発に関する質問や案件のご相談などがある場合、ぜひ弊社Jiteraにお手伝いさせてください。



