
音声認識APIは、プログラムやアプリケーションが、音声をテキストに変換するための機能です。
音声認識APIがあることで、高い精度で文字起こしができたり、容易に機能面の拡張ができたりします。
一般的に、音声認識APIを活用して文字起こしされます、実際にはどのように行うのでしょうか。
この記事では、音声認識APIの基本知識や文字起こしのやり方や、おすすめのツール10選などを解説します。
本記事を読んで、自社で音声認識APIを活用できるかについてご判断ください。
なお、音声認識APIツールと自社のシステムとの連携を検討している場合は、株式会社Jiteraまでお問い合わせください。
AIを使ったシステム開発が得意であり、これまでに多くの開発案件に関わっています。無料でご提案していますので、ぜひご連絡ください!
音声認識APIとは?
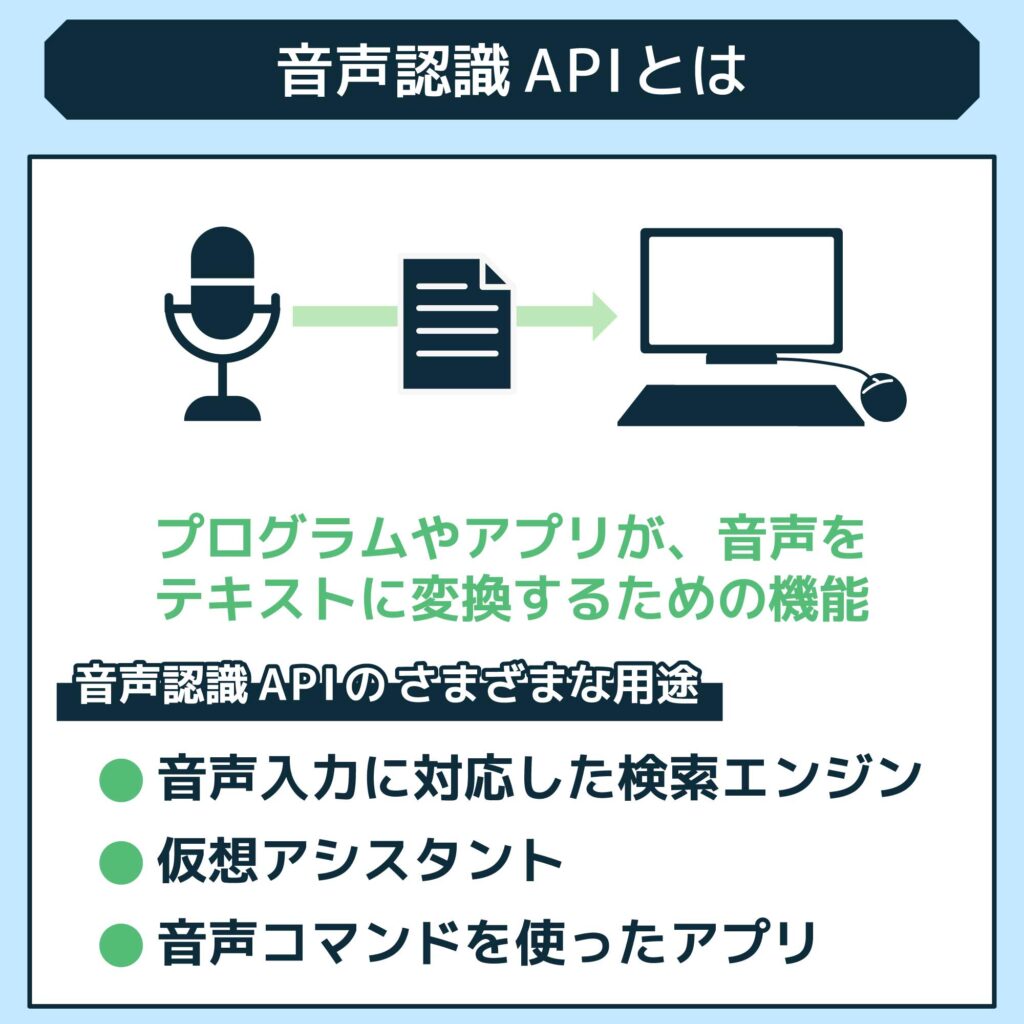
音声認識APIは、プログラムやアプリケーションが、音声をテキストに変換するための機能です。
このAPIを利用することで、音声を入力として受け取り、コンピューターが理解可能なテキストに変換することができます。
音声認識APIは、さまざまな用途で利用されています。
たとえば、以下のようなものです。
- 音声入力に対応した検索エンジン
- 仮想アシスタント
- 音声コマンドを使ったアプリケーション
これらのAPIは、音声からテキスト変換を行うだけでなく、そのテキストを解析して意味を理解する機能が備わっている場合も多くあります。
音声認識APIは、クラウドベースで提供されることが多く、開発者がそのAPIにアクセスして、自分のアプリケーションに組み込むことが可能です。
主要なプラットフォームやサービスプロバイダーが音声認識APIを提供しており、利用することで開発者が独自に音声認識システムを構築する手間を省くことができます。

音声認識APIを使用するメリット

音声認識APIを使用するメリットは以下の通りです。
- 効率化
- 品質向上
- 機能の向上性
それぞれ見ていきましょう。
効率化
音声認識APIを使用することで、開発者は音声認識機能を一から実装する必要がなくなります。
APIが提供する既存の機能を活用することで、開発時間とコストを大幅に削減が可能です。
音声認識は、音響モデル、言語モデル、発音辞書など、複雑な要素で構成されています。これらを独自に開発するには、専門的な知識と膨大な時間が必要です。
しかし、音声認識APIを使用すれば、これらの複雑な処理を APIが担当してくれるため、開発者はアプリケーションのほかの部分に集中できます。
また、音声認識の処理をAPIに委ねると、アプリケーションのパフォーマンスを向上させられます。
その技術に詳しくないエンジニアであっても、多くの時間をかけずにキャッチアップができるため、効率アップが狙えるのではないでしょうか。
品質向上
音声認識APIは、大量の音声データを使用して訓練された高度なモデルを利用しています。
これらのモデルは、膨大な量の音声データで訓練されているため、個別の開発者が実装するよりも高い精度で音声認識を実施することが可能です。
例えると、スーパーに売っているカレーのセット具材のようなものです。完成するまでの一部の機能がすでに存在するため、開発者はスムーズに作業を進められます。
APIを使用することで、言語モデルの継続的な改善や更新の恩恵を受けられ、常に最新の音声認識技術を利用できます。
機能の向上性
音声認識APIは、音声認識だけでなく、話者識別、感情分析、言語識別など、さまざまな付加機能を提供している場合があります。
これらの機能を活用すると、アプリケーションの機能を拡張し、ユーザーにより豊かな体験を提供できます。よりユーザーのニーズにマッチしたサービスを提供できるため、顧客満足度を向上することが可能です。
また、APIのバージョンアップによって新機能が追加された場合、それらの機能を容易に取り入れられるため、アプリケーションの継続的な改善ができるようになります。

音声認識APIを選択する際の重要なポイント

音声認識APIは、プログラムやアプリケーションが音声をテキストに変換するための機能とお伝えしました。
では、どのように音声認識APIを選ぶとよいのでしょうか。
ここでは、音声認識APIを選ぶ際の、以下5つのポイントを解説します。
- 音声認識の精度は高いか
- 必要な機能はあるか
- コストは妥当か
- 用途に合った導入形態があるか
- 必要な対応言語があるか
それぞれのポイントをおさえて、自社でどのように利用できるか検討ください。
音声認識の精度は高いか
音声認識精度は、音声認識APIを選ぶポイントの1つです。
提供する音声認識の精度が高いことが重要であり、認識率が高いほど、ユーザーエクスペリエンスが向上して正確なテキスト変換が得られます。
精度が高いかどうかは、実際の使用例やベンチマークテスト結果を参考にするとよいでしょう。
選択したAPIがサポートする言語がどれであるかも重要なポイントです。
特定の言語や方言をサポートしているかどうかを確認し、プロジェクトの要件に合うAPIを選ぶようにしましょう。
APIのカスタマイズが可能であれば、特定の使用ケースに適した設定を行うことができ、便利です。
ほかにも、音声認識をリアルタイムで行う場合は、APIの応答時間が重要なポイントとなります。
遅延が少なく、高速に動作するAPIを選ぶことで、ユーザエクスペリエンスを向上させられるでしょう。
必要な機能はあるか
音声認識APIを選ぶ際には、プロジェクトやアプリケーションの要件に応じて、必要な機能を考慮することが重要です。
たとえば、リアルタイム認識機能があれば、APIがリアルタイムに音声を認識しサポートしてくれるため、遅延を最小限におさえた高速な認識を行えるでしょう。
ほかにも、騒音が多い環境での音声認識を行う場合は、ノイズ除去機能が便利です。
音声認識APIが、対応する言語を正確に把握しておくことも、重要なポイントです。
アプリケーションの規模が拡大する場合、APIがスケーラブルなソリューションを提供しているかどうか確認しましょう。大量のリクエストや同時ユーザー数に対応できるかどうかが、重要なポイントとなります。
これらの機能を考慮しながら、プロジェクトの要件に適した音声認識APIを選択しましょう。
コストは妥当か
コストは、音声認識APIを選ぶ際の重要な要素の1つです。
APIの利用料金は、プロジェクトやアプリケーションの予算に合わせて考慮する必要があります。
APIが提供する料金体系を調査し、利用料や機能ごとの価格設定を確認しましょう。
多くのAPIプロバイダーは、無料枠や使用期間を提供しています。この無料期間を利用して、APIの機能や性能を評価して、適切なプランを選択するのがおすすめです。
利用料金以外にも、データ転送料や機能の追加料金などの、隠れたコストにも注目しなければなりません。
ほかにも、プロジェクトの成長や利用料の増加によって、API利用料金がどのように変動するか考慮することも重要です。
これらのポイントを考慮しながら、プロジェクトの要件や予算に合った、音声認識APIを選択するようにしましょう。
用途に合った導入形態があるか
音声認識APIを導入する際は、その導入形態も重要な要素です。
導入形態には、以下の2つがあります。
- クラウドベースのAPI
- オンプレミスのソリューション
クラウドベースのAPIは、高い可用性とスケーラビリティを提供します。
サーバー側のインフラストラクチャをAPIプロバイダーが管理するため、迅速に導入できるのがメリットです。
一方で、インターネット接続が必須であり、ほかにも、プライバシーやセキュリティの懸念があることに注意が必要です。
オンプレミスのソリューションでは、データやセキュリティに関する管理を自社で行えるのがメリットです。
データが企業内部に残るため、プライバシーやセキュリティの懸念を軽減できるでしょう。
一方、導入やメンテナンスにより高い初期コストがかかる場合があるため、注意が必要です。
サーバーの導入やセットアップ、運用コストなどが考慮される必要があります。
どちらの導入形態がプロジェクトや組織にとって適切かは、要件や制約によって異なるため、プロジェクトごとの適切な導入形態を選択するようにしましょう。
必要な対応言語があるか
対応言語は、音声認識APIを選ぶ際の重要なポイントの1つです。プロジェクトやアプリケーションが対応する言語に合致するAPIを選ぶことが重要です。
まずは、APIがよく使われる主要な言語をサポートしているかどうかを確認しましょう。
英語・日本語・中国語など、広く利用されている言語がサポートされていることが一般的です。
特定の地域や方言を対象としている場合、APIがその地域や方言を適切に認識できるかどうかを核にするようにしましょう。
たとえば、英語の場合でも米国英語やイギリス英語などの地域や、異なる方言に対応しているかどうかを確認します。
複数言語の同時認識をサポートしているかどうかを確認することも、重要なポイントの1つです。
特に多言語環境での使用や、多言語スピーカー向けのサービスを提供する場合には、重要となるでしょう。
音声認識APIを使った文字起こしのやり方
音声認識APIを選ぶポイントには、さまざまなポイントがあることがわかりました。
では、実際にどのような文字起こしを行うのでしょうか。
ここでは、2種類の方法での、音声認識APIを使った文字起こしの方法を紹介します。
- 音声認識APIを直接利用する方法
- 文字起こしアプリやソフトを使用する方法
それぞれの事例を参考に、自社でも音声認識APIが活用できるかの参考にしてください。
音声認識APIを直接利用する方法
音声認識APIを直接利用して文字起こしを行う方法は、以下のとおりです。
- APIの選定
- APIのアクセス設定
- 開発環境の準備
- APIの呼び出し
- 音声ファイルのダウンロード
- 文字起こしの取得
- 結果の処理
まずは、適切な音声認識を選定します。この際、APIの料金体系や対応言語、精度などを考慮して選択するようにしましょう。
次に、選定したAPIにアクセスするためのアカウントを作成し、APIキーなどの認証情報を取得します。認証情報を取得したら、開発に必要な環境を整えます。
プログラミング言語やフレームワーク、開発ツールなどを選定して環境をセットアップします。環境をセットアップした後、APIを呼び出し音声ファイルから文字起こしを行うための、プログラムを実装します。
APIのドキュメントやサンプルコードを参考に、APIを呼び出すコードを実装しましょう。
プログラムを実装したら、音声ファイルをAPIにアップロードし、文字起こしを実行します。APIからのレスポンスを受け取って、文字置きし結果を取得し、その結果を処理すればデータを取得できます。
取得したデータは、表示や保存などの目的に利用が可能です。
これら手順に従って、音声認識APIを直接利用して文字起こしを行うことができます。
文字起こしアプリやソフトを使用する方法
音声認識APIを活用した文字起こしアプリやソフトウェアを使用する方法は、以下のとおりです。
- アプリやソフトウェアの選択
- アカウントの作成
- 音声ファイルのアップロード
- 音声認識の実行
- 文字起こしの結果の確認
- 結果の保存や出力
まずは、音声認識APIを活用した、文字起こしアプリやソフトウェアを選択します。
それぞれのアプリやソフトウェアの特徴や利点・価格などを比較し、プロジェクトやニーズに合ったものを選択します。
選んだアプリやソフトウェアにアカウントが必要な場合は作成します。アカウントを作成したら、文字起こしを行いたい音声ファイルを選択し、アプリやソフトウェアにアップロードします。
一部のアプリやソフトウェアでは、直接録音することも可能です。
選択したアプリやソフトウェアの音声認識機能を使用して、音声ファイルの文字起こしを実行します。
音声認識が完了すると、文字起こし結果が表示されます。結果を確認して、必要に応じて編集や修正を行うことが可能です。
最後に、文字起こしをした結果を、必要な形式に出力したり保存したりします。
多くのアプリやソフトウェアでは、テキストファイルやドキュメントファイルとして保存することが可能です。
上記の手順に従って、音声認識APIを活用した文字起こしアプリやソフトウェアを使用することができます。
【無料あり】音声認識APIおすすめ10選

音声認識APIには、2つの文字起こし方法があることがわかりました。
では、どのような音声APIがあるのでしょうか。
以下は、音声認識APIのそれぞれの一覧表です。
| サービス名 | 料金 | オンライン利用できるか |
| Google Cloud Speech-to-Text | 音声の量が 1 秒単位で測定され、月単位で料金が設定される | 利用可能 |
| AmiVoice | 1時間99円(税込み)から利用可能 | 利用可能 |
| OpenAI Whisper | 1時間利用した場合約50〜60円です。 | 利用可能 |
| Watson Speech to Text | 1 分あたり 0.01 ドル (USD) | 利用可能 |
| Azure Speech Service | 1時間あたり149.605円(標準の場合) | 利用不可 |
| Amazon Transcribe | 1 か月に文字起こしを行った音声の秒数に基づいて、従量課金制で料金が発生 | 利用可能 |
| NTT SpeechRec | <クラウド版>初期登録料:15万円(税別)利用料:月額12万円(税別)〜<オンプレ版>構築費:15万円(税別)〜ライセンス料:月額12万円(税別)〜 | 利用不可 |
| AmiVoice ScribeAssist | 月額80,000円〜 | 利用可能 |
| VOSK | 無料 | 利用可能 |
| Sloos | 無料 | 利用可能 |
ここからは、 費用を抑えたい中小企業に向けて、無料で利用可能な音声認識APIを紹介します。
Google Cloud Speech-to-Text

出典:https://cloud.google.com/speech-to-text?hl=ja
Google Cloud Speech-to-Textは、Googleが提供する音声文字起こしサービスです。音声認識の精度が高く、多くの言語に対応しているとして評価されています。
Google Cloud Speech-to-Textは、機械学習を活用して音声データをテキストに変換します。対応する音声データは、.wavや.flacなどの音声ファイルや、マイクから入力されるストリーム形式などです。
Google Cloud Speech-to-Textは、Google Cloud Platform(GCP)の1サービスとして提供されているため、利用にはGCPのアカウントが必要です。
Googleによると、データの共有に同意した顧客からの提供データをAIに学習させることでサービスの性能が向上し、単語の誤りも半分以下に減ったとしています。
AmiVoice
出典:https://www.scsk.jp/product/common/speech_recognition/index.html
AmiVoice(アミボイス)は、会話を自動でテキスト化する音声認識技術と、その技術を搭載した音声認識エンジンの総称です。
AmiVoiceは、25年以上の実績を持ち、日本語や専門用語に強いAI音声認識技術です。多くの官公庁、医療機関やコールセンターなどの業務効率化に幅広く導入されています。
個別の企業に合わせた用語(辞書)を設定し、コンタクトセンターで活用するためのさまざまな機能を提供しています。
日本語・ビジネスに特化しており、AI技術によりあらゆる人、言葉、会話スピードに対応が可能です。元の音声をテキストデータとともに保存が可能であり、ハイクオリティーかつハイスピードな処理能力をもっています。
OpenAI Whisper
出典:https://openai.com/research/whisper
OpenAIのWhisperは、音声情報をテキストデータに変換することが可能な、無料で利用できる音声認識 APIです。インターネット上から収集した、大量の音声データを機械学習させることで、文字起こしを高い精度で行うことができます。
Whisperでは、日本語を含む98言語の識別・文字起こし・音声英訳が可能です。
5つのモデルサイズで精度を調整することが可能で、主にビジネスや個人利用で幅広く活用されており、議事録作成やインタビュー記事の執筆などにも役立ちます。
Whisperは、一般的な文字起こしツールに比べて比較的安価に利用できるのが特徴的です。
Watson Speech to Text

出典:https://www.ibm.com/jp-ja/products/speech-to-text
Watson Speech to Textは、IBM が提供する音声をテキストに変換する API です。機械学習を活用して、文法、言語構造、および音声シグナルの構成に関する知識を組み合わせ、人間の音声を正確に書き起こします。
Watson Speech to Textは、SaaSとしても、セルフホスティングとしても利用できます。リアルタイムでの音声認識とテキスト化を実現できるため、聞き漏らしが許されない場面でも記録として残すことができます。
Watson Speech to Textでは、独自の文書を登録してカスタムモデルをつくることも可能です。社内用語等が入った文書を登録することで、より正確な音声認識が可能となるでしょう。
Bing Speech API
出典:https://learn.microsoft.com/ja-jp/azure/ai-services/speech-service/
Azure Speech Service は、Azure Cognitive Services が提供するサービスの1つで、音声翻訳や音声合成、音声認識などの機能をAPIで利用が可能です。
音声サービスでは、音声データを入力として取り込み、音声テキストへ変換しそのテキストを読み上げる機能が利用できます。
テキストの文字起こしでは、高精度な音声再生が可能で、自然に聞こえるテキスト読み上げを実現しています。
ほかにも、翻訳機能や会話中に話者を認識する機能もあるため、便利です。
Amazon Transcribe
出典:https://aws.amazon.com/jp/transcribe/
Amazon Transcribeは、Amazon Web Service(AWS)が提供する自動音声認識サービスです。機械学習モデルを使用して、音声をテキストに変換します。
Amazon Transcribeは、スタンドアロンの文字起こしサービスとして使用することも、アプリケーションに機能を追加することもできます。
カスタマイズ可能な機能が用意されており、ユーザーは、ビジネスニーズに合わせて音声認識モデルを構築可能です。カスタム語彙、機密情報の削除、言語識別などがカスタマイズオプションとして利用できます。
Amazon Transcribeは、カスタマーサービスでの通話の内容を文字で起こしたり、字幕を自動で付けたりするほか、メディア資産のメタデータの生成や、臨床文書アプリケーションへの医療用音声の追加などもできます。
NTT SpeechRec

SpeechRecは、NTTテクノクロスが開発した最先端の音声認識エンジンを搭載した、さまざまな環境下で動作する高精度な音声認識(Automatic Speech Recognition, ASR)ソリューションです。マイクから入力された音声や、電話経由の自由発話を高精度な音声変換が可能です。
NTT独自の音声認識技術に基づいており、高い認識精度を実現しています。日本語のみならず、英語などの他の言語にも対応しており、文字起こしが可能です。
ほかにも、リアルタイムでの音声認識処理が可能です。ストリーミング形式での音声入力にも対応しており、リアルタイム性が求められるさまざまなアプリケーションに利用できます。
安全性とセキュリティに配慮して設計されており、音声データの送信や処理は、SSL暗号化通信を介して行われます。
APIを介して提供されているためクラウドベースで利用できるほか、オンプレミス環境に導入して利用でき、企業や開発者が自身のニーズに合わせて柔軟に利用が可能です。
AmiVoice ScribeAssist

出典:https://www.advanced-media.co.jp/lp/scribeassist/
AmiVoice ScribeAssist(アミボイス スクライブアシスト)は、株式会社アドバンスト・メディアが提供する文字起こしアプリケーションで、音声録音からテキスト化、編集までをワンストップで行うことができます。
リアルタイムで音声認識をしながら、その場で起こした文字を編集することも可能です。また、後から音声を取り込んで認識することもできます。
AmiVoice ScribeAssistは、インターネット未接続でも使用可能なスタンドアローン型システムです。インストールタイプのアプリなのでデータ処理が全てPC内で行われるため、情報漏洩リスクを抑えることができます。
AmiVoice ScribeAssistは、WEB会議や商談、会見など、対面や非対面問わず多くのシーンでの利用が可能です。多くのオンラインの会議システムとの併用ができ、議事録を作成する際に役立つ機能が多く搭載されているアプリケーションとなっています。
VOSK
出典:https://alphacephei.com/vosk/
VOSK(Database Connection Serverの略称)は、米国マイクロソフト社が提唱するデータベースをオープン環境で接続するためのアーキテクチャです。
物理的なファイルからデータに着目してレコードを取り出し、論理的なファイルを作成するファイルです。VOSKはオープンソースの音声認識ツールキットであるため、気軽に利用ができます。
20言語以上のプログラミング言語に対応し、Android・ios・C・C#・GO・Java・NodeJs・Python・Ruby・Rustなどに対応しています。
VOSKのメリットは、オフラインで動作する点です。インストールも容易であり、さまざまなプラットフォーム上で動作します。特にMacOSの場合、M1にも対応しています。
VOSKは、チャットボット、スマートホーム家電、バーチャルアシスタントなどに音声認識を提供します。また、映画の字幕や講演会の文字起こしなども作成が可能です。
Sloos
Sloos(スルース)は、音声を文字に変換する無料のサービスです。汎用的なマイク1台で最大10名までの話者を識別し、発言内容をリアルタイムで文字起こししてくれます。
Sloosは、レザバーコンピューティングを利用した話者認識技術を有しています。対面の会議やオンライン会議システム(Teams、Zoom、Google Meets、Skypeなど)で使用できます。
音声認識APIで文字起こしをする際の注意点

音声認識APIには、多くのツールがあることがわかりました。
では、音声認識APIで文字起こしする際の注意点には、どのようなものがあるのでしょうか。
ここでは、以下3つの注意点を解説します。
- 音声の品質
- 音声の環境
- 音声の種類
これらの注意点を理解して、音声認識APIを利用するようにしましょう。
音声の品質
音声認識APIを利用する際は、音声の品質に注意が必要です。環境ノイズや雑音が、音声認識の精度に影響することがあります。
特に騒音の多い環境では、音声品質が低下して、認識精度が悪化する可能性があるため注意しましょう。ほかにも、使用するマイクの品質が、音声認識の精度に影響することがあります。
高品質のマイクを使用することで、音声のクリアさや解像度が向上し、認識精度を高めることが可能です。話者の発生の質や明瞭さも、音声認識の精度に影響を与えます。
はっきりとした発音や適切な声量で話すことで、認識精度を向上させることができるでしょう。
音声の環境
音声認識APIを利用する際は、音声の環境に関することに注意が必要です。周囲の騒音や背景雑音が、音声認識の精度に大きく影響します。
騒音の多い環境では、音声と雑音を区別することは難しいでしょう。このような環境では、認識精度が低下する可能性があります。
音声が部屋内で反射してエコーが発生すると、音声認識の精度が低下することがあるため注意が必要です。特に、大きな部屋や吸音材の少ない空間では、エコーの影響が顕著にあらわれるでしょう。
ほかにも、マイクの位置や配置も音声認識の精度に影響を与えます。適切なマイクの位置を選択し、話者に近づけることで、音声品質を向上させることが可能です。
音声の種類
さまざまな種類の音声に注意することは、音声認識APIを利用する際に注意すべき点の1つです。話者の性別・年齢・アクセント・方言など、話者ごとの特徴は音声認識の精度に影響を与える可能性があります。
特に異なるアクセントや方言を持つ話者がいる場合、適切なモデルや設定を選択する必要があるでしょう。
話者の話す速度やリズムも、音声認識の精度に影響を与えることがあります。話し方が早い場合や、リズムが不規則な人だと、認識精度が低下する可能性があるため、注意が必要です。
背景ノイズが混入している場合、音声認識の精度が低下することがあります。特に、騒音の多い環境では、音声とノイズを区別することが難しく、認識精度が低下する可能性が高くなるでしょう。
中小企業での音声認識APIの活用事例

音声認識APIを利用する際は、さまざまな注意点があることがわかりました。
次に、中小企業での音声認識APIの活用事例をみていきましょう。
ここでは、音声認識APIの活用事例として、以下4つの事例を紹介します。
- 株式会社リンク(コールセンター)
- 株式会社アシストメディカル(医療カルテ作成)
- 株式会社ニチコン(音声認識目視入力システム)
- 築地フレッシュ丸都(受注管理)
音声認識APIを実際に活用している企業事例と、その効果についてみていきましょう。
株式会社リンク(コールセンター)

株式会社リンクは、クラウド型コールセンターシステム「BIZTEL(ビズテル)」を展開しています。
BIZTELは、インターネットとPCのみで利用でき、PCI DSS準拠の高セキュリティ要件を満たしたコールセンターです。
このBIZTELに、AmiVoiceの技術が使われています。BIZTELは、クラウド型のPBX、つまり電話のサービスです。
場所を問わず、インターネット回線とパソコンさえあれば、どこでもコールセンターやビジネスフォンが構築できるサービスとなっています。
BIZTELとAmiVoice API を連携させて、電話での通話した内容を音声で認識し、その内容をテキスト化し、BIZTELの管理画面から確認することが可能です。
ほかにも、ユーザーの発話内容に合わせてつなぎ先を変えたり、自動応答を実現する機能「音声認識IVR」を提供しています。
株式会社アシストメディカル(医療カルテ作成)
出典:https://assist-yokohama.co.jp/medical/
株式会社アシストでは、病院内での電子カルテやオーダリングシステム、医事システムなどの導入から運用サポートまでを支援しています。
また、医療データの効果的な活用に必要となるDWHや分析レポートの提供も行っています。
「AmiVoice ScribeAssist」は、AmiVoiceを活用した議事録の書き起こしが可能な、医療法人・社会福祉法人向けの製品です。カンファレンスやWEB会議、商談など、対面・非対面の幅広いシーンで利用できる、スタンドアローン型文字起こし支援アプリケーションです。
各種オンライン会議システムと併用が可能で、議事録を作成する際に役立つ機能を数多く搭載しています。
株式会社ニチコン(音声認識目視入力システム)
出典:https://www.nichicon.co.jp/
株式会社ニチコンは、ポリエチレン製タンクを金属製の外枠で覆った複合コンテナやステンレス製IBCの設計、製造、販売、メンテナンスなどを主な事業とする会社です。
この企業では、株式会社イヤサカの音声認識目視入力システム「CS-iVOICE」を導入しています。
このサービスは、点検箇所を目視で確認し、音声で結果を入力するシステムで、コンパクトなウェアラブル端末によりハンズフリー点検が可能です。
モバイルコンピューターとスマートグラスを採用しており、音声認識で点検記号を自動入力し、効率的な点検結果管理を実現します。
築地フレッシュ丸都(受注管理)

株式会社築地フレッシュ丸都は、国内外の水産物を取り扱う豊洲市場に近い立地条件を生かして、新鮮な魚を加工場にて食卓に届けることを目標としています。
築地フレッシュ丸都の製造部門には、加工部(製造管理・物流管理)があり、取引先からの注文を受け、加工指示書などを作成しています。
これまでは、事務所にて店舗別・魚種別の受注情報をエクセルにて作成後、印刷した紙を加工現場に持ち込み、手書きにて計量した商品重量を記入したのち、あらためて事務所に戻ってPC入力を行っていました。
「AmiVoice Keyboard」を導入することで、こうした手書きとPC入力の二度手間を解消し、業務効率化に成功しています。
これは、Windows OS向けの音声入力ソフトで、音声認識技術を活用して、キーボード上のすべてのキー操作を声で行えます。
入力するキーや文字列、実行する操作をあらかじめ登録しておくことで、Windowsのキーボード操作を声で行うことが可能です。有線マイクや無線マイクを使用して、ハンズフリーでキーボード操作ができます。
まとめ:音声認識APIで業務効率化を目指しましょう

今回は、音声認識APIに関することをみてきて、以下のことがわかりました。
- 音声認識APIはプログラムやアプリケーションが音声をテキストに変換するための機能
- 音声認識APIを選ぶ際は提供される音声認識の精度が高いことが重要
- 文字起こしには音声認識APIを利用する方法とアプリを利用する方法がある
- 音声認識APIには無料で利用できるサービスがある
音声認識APIツールにはさまざまな種類があり、無料で利用できるものもあるため、まずは簡単に使ってみるところから始めるのはいかがでしょうか?
音声APIツールと自社のシステムを連携したい場合は、株式会社Jiteraまでご相談ください。連携することでより効率化できる場合があります。
AIを使ったシステム開発が得意であり、これまでに多くの開発案件に関わっています。無料でご提案していますので、ぜひ問い合わせください!
 メールマガジン登録
メールマガジン登録
