

クラスタリングは、データの類似度に基づいてグループ分けする手法で、AIの機械学習に使われる教師なし学習です。
クラスタリングには「階層的クラスタリング」と「非階層的クラスタリング」の2種類があります。階層的クラスタリングは、似たデータを順にグループ化し、非階層的クラスタリングは最初にクラスタ数を決めてグループ分けします。
この記事では、Pythonを用いた階層的クラスタリングの方法をコード付きで解説します。
コンピュータの専門学校がプログラミング及び、コンピュータの基礎を学び、その後、日本電気の子会社で働きました。その後、いくつかの開発の仕事を経て,コンピュータの専門学校の講師兼担任を経験し、その後はフリーにてシステムエンジニアやプログラマーの開発の仕事を担当、そのかたわらプログラミングスクールや職業訓練所、企業の新人教育などを担当しました。 25年以上のシステムエンジニア、プログラマーの仕事の経験があります。
Pythonでの階層的クラスタリングの実装準備

Pythonで階層的クラスタリングを行うには、以下のような準備が必要となります。
-
- 必要なライブラリのインストール
- データセットの準備
以下では、上記について詳しく説明していきます。
必要なライブラリのインストール
Pythonで階層的クラスタリングを行うのに必要なライブラリは以下のとおりです。
| ライブラリ名 | 用途 |
| SciPySciPy | 科学技術計算のためのライブラリで、[scipy.cluster.hierarchy]モジュールに階層的クラスタリングの関数が含まれています。このモジュールを使用すると、データセットを階層的にクラスタリングできます。 |
| scikit-learn | Pythonの主要な機械学習ライブラリで、多くのクラスタリングアルゴリズムをサポートしています。階層的クラスタリングだけでなく、K-meansやDBSCANなどの標準的なクラスタリング手法も利用できます。 |
| NumPy | 数値計算ライブラリで、多次元配列の操作や高速演算(実際はC言語で書かれているため)ができる基本的な演算処理ができます。 |
| Pandas | データ整形用ライブラリの1つです。主にデータ解析や加工、集計、分析処理に利用されます。 |
| matplotlib.pyplot | データ可視化ライブラリであり、グラフを描画するためのモジュールです。 |
ライブラリは、import文を使ってプログラムに追加します。
import pandas as pd
from scipy.cluster.hierarchy import linkage, dendrogram
import matplotlib.pyplot as plt
以下は、身長と体重のデータを使った階層的クラスタリングのサンプルコードです。(scipyライブラリを使っています。)
import pandas as pd
from scipy.cluster.hierarchy import linkage, dendrogram
import matplotlib.pyplot as plt# データの初期化
data = pd.DataFrame({
‘身長’: [160, 170, 175, 180],
‘体重’: [60, 65, 80, 75]
})# 距離行列の計算
distance_matrix = linkage(data, method=’ward’)# デンドログラムの作成
plt.figure(figsize=(8, 6))
dendrogram(distance_matrix, labels=data.index)
plt.xlabel(‘データ番号’)
plt.ylabel(‘距離’)
plt.title(‘階層的クラスタリングのデンドログラム’)
plt.show()
このコードでは、[linkage関数]を使用して距離行列を計算し、[dendrogram関数]で『デンドログラム』を作成しています。デンドログラムはクラスタリングの過程を可視化するための図です。以下のような図を出力します。

データセットの準備
クラスタリングの分析には良質で、整ったデータが必要です。そのため事前にデータのクリーニング(欠損値の処理・外れ値の特定と対応・重複データの削除)が不可欠となります。
また、データの正規化ということも必要です。以下は階層的クラスタリングを行う前にデータの正規化を行う例です。
※データセットはirisというすでに用意されているデータセットを使っています。
from sklearn.preprocessing import StandardScaler# Irisデータ読み込み
iris = load_iris()
df_iris = iris.data# データの正規化(平均0, 標準偏差1)
scaler = StandardScaler()
df_iris_std = scaler.fit_transform(df_iris)
続いて、sklearn.clusterライブラリを使った階層的クラスタリングの例です。
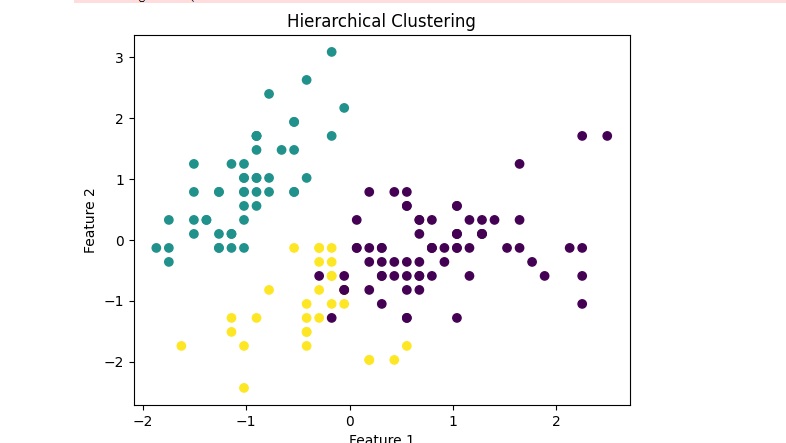
import matplotlib.pyplot as plt# 階層的クラスタリングの実行
clustering = AgglomerativeClustering(n_clusters=3, affinity=’euclidean’, linkage=’ward’)
clusters = clustering.fit_predict(df_iris_std)# クラスタリング結果を可視化
plt.scatter(df_iris_std[:, 0], df_iris_std[:, 1], c=clusters, cmap=’viridis’)
plt.xlabel(‘Feature 1’)
plt.ylabel(‘Feature 2’)
plt.title(‘Hierarchical Clustering’)
plt.show()
上記を実行すると以下のような結果を得られます。
Pythonでの階層的クラスタリングの実装手順

事前に説明したことと重複するかもしれませんが、ここではさらにPythonでの階層的クラスタリングの実装手順を説明します。
階層的クラスタリングは、データ間の近似値によってグループ化を行う方法です。
1.データの距離を算出し、距離行列というものを最初に作成する
2.その距離行列を使って、クラスタを作ります。(近い距離のものをグループ化する。)
3.出来たクラスタ同士で、距離行列を更新する。
2と3を結果、一つのクラスタにまとまるまで繰り返します。
※それを凝集型クラスタリングと呼びます。
最後にクラスタの可視化を行います。
距離を計算する方法に、ユークリッド距離やマンハッタン距離などがあります。
以下、単純にユークリッド距離を使って距離行列を作る例です。
from scipy.spatial.distance import pdist, squareform# サンプルデータ(5つのデータポイント)
data = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]])# ユークリッド距離を計算
distance_vector = pdist(data, metric=’euclidean’)# 距離行列を復元
distance_matrix = squareform(distance_vector)print(“距離行列:\n”, distance_matrix)
結果は以下のようになります。
-
- 距離行列:
-
- [[ 0. 2.82842712 5.65685425 8.48528137 11.3137085 ]
-
- [ 2.82842712 0. 2.82842712 5.65685425 8.48528137]
-
- [ 5.65685425 2.82842712 0. 2.82842712 5.65685425]
-
- [ 8.48528137 5.65685425 2.82842712 0. 2.82842712]
- [11.3137085 8.48528137 5.65685425 2.82842712 0. ]]
距離行列の計算
先程、距離行列のコード例を提示しましたが、もう少し複雑なものを見てみます。
import numpy as np# 初期値データ
initial_data = np.array([[0, 1], [1, 0], [2, 3], [4, 2], [3, 5], [6, 1]])# 距離行列の計算
def calculate_distance_matrix(data):
num_samples = len(data)
distance_matrix = np.zeros((num_samples, num_samples))
for i in range(num_samples):
for j in range(num_samples):
distance_matrix[i, j] = np.sqrt(np.sum((data[i] – data[j]) ** 2))
return distance_matrix
上記のサンプルの説明です。
- 初期値データの定義: initial_dataという配列に初期値データを定義しています。これはクラスタリングの対象となるデータです。
- 距離行列の計算: calculate_distance_matrix関数では、与えられたデータに対して距離行列を計算しています。ここでは、ユークリッド距離を使用しています。
次の凝集型階層的クラスタリングの実装にプログラムは続きます。
凝集型階層的クラスタリングの実装
凝集型階層的クラスタリングをおこなう関数です。距離行列の計算で提示したプログラムの続きになります。
def hierarchical_clustering(distance_matrix):
num_samples = distance_matrix.shape[0]
clusters = [[i] for i in range(num_samples)]
dendrogram = []while len(clusters) > 1:
min_distance = np.inf
for i in range(len(clusters)):
for j in range(i + 1, len(clusters)):
cluster1 = clusters[i]
cluster2 = clusters[j]
distance = min([distance_matrix[p1, p2] for p1 in cluster1 for p2 in cluster2])
if distance < min_distance:
min_distance = distance
merge_i, merge_j = i, jdendrogram.append([merge_i, merge_j, min_distance, len(clusters[merge_i]) + len(clusters[merge_j])])
clusters[merge_i].extend(clusters[merge_j])
del clusters[merge_j]return clusters, dendrogram# 距離行列の計算
distance_matrix = calculate_distance_matrix(initial_data)# 凝縮型階層クラスタリング
clusters, dendrogram = hierarchical_clustering(distance_matrix)
print(clusters)# デンドログラムの作成
def plot_dendrogram(dendrogram):
plt.figure(figsize=(10, 5))
plt.title(‘Dendrogram’)
for i in range(len(dendrogram)):
x = [i, i]
y = [dendrogram[i][2], dendrogram[i][3]]
plt.plot(x, y, color=’b’)
plt.show()plot_dendrogram(dendrogram)
上記のプログラムの説明です。
- 凝縮型階層クラスタリングの実装: hierarchical_clustering関数では、凝縮型階層クラスタリングアルゴリズムを実装しています。このアルゴリズムでは、最も近いクラスタのペアをマージしていき、全てのデータが1つのクラスタになるまで繰り返します。
- hierarchical_clustering関数がクラスタの結合過程を示すdendrogramを返しています。その後、plot_dendrogram関数を使用して、dendrogramを可視化しています。
上記のプログラムは実は、SciPyのscipy.cluster.hierarchyモジュールを使うと簡単に記述することができます。
ZA = linkage(data, method=’ward’)
上記のlinkage関数を使うと、距離行列を計算してクラスタリングまでおこなってくれます。linkage関数については次の節で説明しています。
リンケージ方法の指定
linkage引数でリンケージ方法を指定することができます。リンケージとは、2つのクラスタ間の距離を測る方法のことです。代表的なリンケージ方法は以下の通りです。
- ward: 近しい情報量をもつ2つのクラスタの結合を重視する。もっとも自然な分類が行われる。
- complete: 最長の結合(クラスタ間の最大距離)を計算する。
- average: 全ての結合の平均距離を計算する。
- single: 最短の結合(クラスタ間の最小距離)を計算する。
linkage=’ward’がデフォルト値なので、こだわりがなければこのままでよいでしょう。
デンドログラムの可視化

今回は、scipyライブラリのcluster.hierarchyモジュールを使用します。
dendrogram関数に、linkageで計算したクラスタリング結果を引数として渡すことで、デンドログラムの可視化ができます。
from scipy.cluster.hierarchy import linkage, dendrogram# デンドログラムの表示
Z = linkage(X, ‘ward’)
dendrogram(Z)
linkageメソッドでリンケージ行列を計算し、dendrogramメソッドでプロットされ、デンドログラムが作成されます。
以下が実際のコードです。

こちらが表示結果です。codecluster.fit_predict(X)により、距離計算の過程も出力されていますが、煩雑なため省略しています。
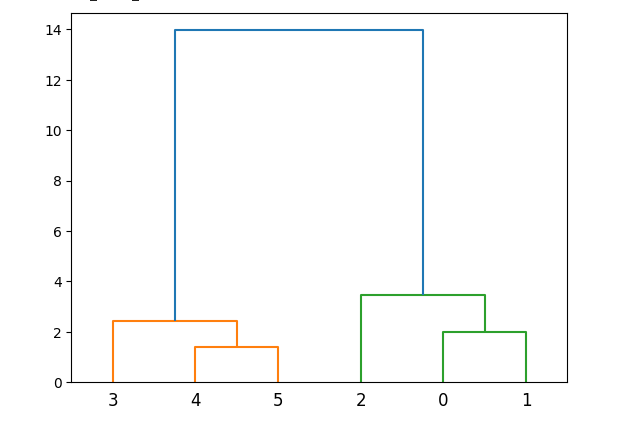
無事、デンドログラムが表示されましたね。
デンドログラムを見ることで、クラスタリングの様子や適切なクラスター数を決められます。わずか数行のコードで実装できる点も、階層的クラスタリングの利点の一つといえるでしょう。
クラスタリングの評価指標

クラスタリング分析を行う際、その結果の質を評価するためには適切な評価指標が必要です。これらの指標は、クラスタリングがどれだけ効果的にデータをグループ化しているかを定量的に示すもので、アルゴリズムの選択やパラメータ調整の基準として用いられます。
主な評価指標には、シルエットスコア、エルボー法、Davies-Bouldinインデックスなどがあります。これらの指標を理解し適切に使用することで、クラスタリングの性能を最適化し、より有意義なデータの洞察を得ることが可能になります。
シルエット係数
シルエット係数は、クラスタリングの結果の品質を評価するための指標の一つです。この係数は、クラスタ内のデータポイントがどれだけ密集しているか、そして異なるクラスタのデータポイントとどれだけ遠く離れているかを測定することにより、クラスタリングの有効性を数値化します。シルエット係数の値は -1 から 1 の範囲で、値が高いほどクラスタリングの品質が良いとされています。
具体的には、各データポイントに対して計算されるシルエットスコアは、そのデータポイントが所属するクラスタ内の他のデータポイントまでの平均距離(a)と、最も近い他のクラスタのデータポイントまでの平均距離(b)を使用して計算されます。
式で表すと、シルエットスコアs は以下のように定義されます:
s= (b−a)/max(a,b)
ここで、
b :異なるクラスタとの分離度を示す
シルエットスコアが 1 に近い値を示す場合、クラスタ内のデータポイントは非常に密接に関連しており、他のクラスタとは明確に分かれていることを意味します。
一方で、スコアが 0 に近い場合は、クラスタの境界が曖昧であるか、データポイントが他のクラスタに近すぎることを示しています。スコアが負の値を取る場合、多くのデータポイントが間違ったクラスタに割り当てられている可能性があります。
シルエット係数を活用することで、クラスタリングのパラメータ調整や、異なるクラスタリング手法の比較に役立つ洞察を得ることができます。この係数は、クラスタリングが適切に行われているかを定量的に評価するための重要なツールとなっています。
エルボー法
エルボー法は、クラスタリング分析において最適なクラスタ数を決定するための一般的な手法です。この方法は、クラスタ数とそれに対応するクラスタリングの成果を表すコスト(例えば、クラスタ内誤差平方和)の関係をプロットし、プロットした曲線が「肘」のように見える点を探すことに基づいています。この「肘」の点は、追加のクラスタが全体の成績をあまり改善しないことを示しており、適切なクラスタ数を示唆しています。
エルボー法を使用するプロセスは、異なるクラスタ数に対してクラスタリングアルゴリズム(例えばK-means)を複数回実行し、各ケースのクラスタ内誤差平方和(SSE)を計算します。SSEは、クラスタ内の各データポイントとクラスタの中心との距離の二乗和であり、値が小さいほどデータ点がクラスタの中心に近く、クラスタリングが効果的であることを意味します。
import matplotlib.pyplot as plt# データの生成
data = np.random.rand(100, 2)# SSEの格納リスト
sse = []
for k in range(1, 11):
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(data)
sse.append(kmeans.inertia_) # SSEをリストに追加
plt.plot(range(1, 11), sse, marker=’o’)
plt.xlabel(‘Number of clusters’)
plt.ylabel(‘SSE’)
plt.title(‘Elbow Method’)
plt.show()
このグラフにおいて、SSEが急激に減少するところから緩やかになる「肘」のような点を探します。
この点が最も効果的なクラスタ数を示しています。エルボー法は直感的であり、多くの場合において初期のクラスタ数の選定に有効ですが、すべてのデータセットや状況で明確な「肘」が見つかるとは限らないため、他の指標と併用することが推奨されます。
クラスタリングの応用分野

クラスタリング技術はその汎用性から、様々な産業や研究分野で活用されています。この手法は、ビッグデータのインサイト抽出から社会科学、医療、金融サービスまで、広範囲な応用が可能です。データセット内の自然なパターンやグループを発見する能力により、クラスタリングは特に顧客セグメンテーション、画像処理、遺伝子解析などの分野で重宝されています。このセクションでは、これらの応用例を深掘りし、クラスタリングがどのように実世界の問題解決に貢献しているかを探ります。
機械学習におけるクラスタリング
機械学習において、クラスタリングはデータの前処理や探索的データ分析に広く用いられる手法です。この教師なし学習アプローチは、ラベルが未割り当ての大量データから有意義なパターンを発見するのに役立ちます。特に、新しいデータセットに対する初期の洞察を得るためや、データの内在する構造を理解する上でクラスタリングは重要な役割を果たします。
クラスタリングは、機械学習プロジェクトにおけるデータセットの特徴を把握するための効果的な手段です。例えば、顧客データベースがある場合、クラスタリングを適用して顧客を異なるセグメントに分けることができます。これにより、類似の行動や嗜好を持つ顧客グループを特定し、ターゲットマーケティング戦略やパーソナライズされたサービスの提供が可能になります。
これらの活用事例からもわかるように、クラスタリングは機械学習アプリケーションを強化し、多様なビジネスニーズに応えるための強力なツールです。データの洞察を深め、効率的な意思決定を支援するために、クラスタリングの重要性は今後も高まることでしょう。

まとめ:基礎から応用まで

クラスタリングとは、大量のデータをデータの近似値によってグループ分けをすることによって、データのパターンや異常値の検出などを行います。
クラスタリングには、階層的クラスタリングと非階層的クラスタリングがあります。
Pythonでプログラムをするとどちらのクラスタリングも比較的に、簡単に構築することができますが、この記事では階層的クラスタリングを行う実装方法について説明しました。
階層的クラスタリングを行う際に必要なライブラリの紹介と、ライブラリを使っての距離行列の計算や、凝集型階層的クラスタリングの実装について実際のコードを紹介しています。
また、クラスタリングの評価指標や、クラスタリングを応用する分野についても説明しています。

弊社では、要件定義をするだけでAIがシステム・アプリを開発するプラットフォーム「JITERA」を軸として、独自のAIプロダクト・最新技術を使って品質にこだわったシステム・アプリ開発が可能です。
ITに関する知識やシステム開発の経験が無くてもご安心ください。Pythonでの階層的クラスタリングに関することはもちろん、貴社の抱える様々な課題についてご対応させて頂きますので、ぜひ株式会社Jiteraへお問い合わせください。
株式会社Jitera




