

ビッグデータの分析と処理は、現代のビジネスにおいて不可欠な要素となっています。
その中でも、Apache Sparkはその高速性とスケーラビリティ、柔軟性が魅力であり、さまざまなビジネスシーンで活用されています。
この記事では、Apache Sparkの特徴やメリット、具体的な使用方法について詳しく解説します。
ビッグデータを扱うプロフェッショナルから、これからデータ分析を始める方まで、Apache Sparkについて理解を深めたい方は、ぜひ参考にしてみてください。
東京都在住のライターです。わかりづらい内容を簡略化し、読みやすい記事を提供できればと思っています。
Apache Sparkとは

Apache Sparkは、大規模なデータ処理を高速に行うためのオープンソースフレームワークです。 このシステムは、大量のデータを短時間で処理できることが大きな特徴です。
たとえば、Webサイトのログデータや電子商取引サイトのユーザー行動データなど、さまざまなビッグデータを迅速に分析することができます。
その高速処理は、インメモリ計算と呼ばれる技術によって支えられています。インメモリ計算はデータをメモリ内に保持し、ディスクへの読み書きを極力避けることで、処理速度を大幅に向上させられます。 これにより、従来のディスクベースの処理方法よりもはるかに早くデータ分析を行うことが可能なのです。
Apache Sparkの利用は、データサイエンスや機械学習の分野で特に重宝されています。データの前処理から分析、予測モデルの構築に至るまで、一連の流れをスムーズに行えるため、多くの企業が導入を進めています。このフレームワークを活用することで、新たなビジネスの洞察を得たり、効率的な意思決定を行うための強力な支援を受けることができます。
Apache Sparkはビッグデータ技術の中心的な存在となり、今後も多くのイノベーションを生み出していくと期待されています。
Apache Sparkの主な機能とメリット

Apache Sparkの主な機能には、リアルタイム処理やバッチ処理があります。 これにより、さまざまな形式のデータを柔軟に処理できるため、多くのビジネスシーンでの活用が可能です。
ここでは、Apache Sparkのメリットを5つ紹介します。
- 高速処理
- リアルタイム処理
- 豊富なライブラリ
- 簡単な操作性
- スケーラビリティ
それぞれ詳しく解説します。
高速処理
Apache Sparkの高速処理能力は、データ分析タスクの効率を大幅に向上させます。 これは、インメモリ計算を活用し、データをRAMに保持することで実現されます。この方式により、ディスクI/Oの遅延が減少し、計算速度が飛躍的に向上します。
たとえば、大手通販サイトでの売上分析を行う場合、過去の販売データを数分で分析し、即座にマーケティング戦略を調整することが可能です。
この迅速なデータ処理は、タイムリーなビジネス意思決定を支援し、市場の変動に素早く対応するための強力なツールとなります。
このように、Apache Sparkはデータを迅速に処理し、洞察を速やかに提供することで、企業の競争力を高める重要な役割を担います。
リアルタイム処理
Apache Sparkはリアルタイムデータ処理にも優れています。 この機能は、ストリーミングデータを連続的に受け取り、ほぼリアルタイムで分析を行うことができる点にあります。これにより、企業は瞬時にデータからのフィードバックを得ることが可能です。
たとえば、ソーシャルメディアのトレンド分析を行う際、リアルタイムでユーザーの投稿を分析し、流行の話題やユーザーの反応を即座に把握することができます。このように素早く分析が行えるため、マーケティング戦略や製品開発において重要な分析を効率化し、素早く対応することが可能です。
リアルタイム処理を活用することで、ビジネスの機動力を格段に向上させ、市場変動に対する迅速な対応が実現されます。
豊富なライブラリ
Apache Sparkは豊富なライブラリを提供しており、これが多様なデータ処理ニーズに応えます。 これには、MLlib(機械学習ライブラリ)、GraphX(グラフ処理ライブラリ)、そしてSpark SQL(SQLとデータフレーム操作のサポート)などが含まれます。
たとえば、MLlibを使用することで、予測モデルの開発やデータのクラスタリング、分類などの複雑な機械学習タスクを簡単に実行可能です。これにより、データサイエンティストはより効率的にデータから洞察を引き出すことが可能になります。
これらのライブラリは、Apache Sparkをただのデータ処理フレームワークから、強力な分析ツールへと変貌させる重要な要素です。 その結果、ビジネスはデータに基づく意思決定を迅速かつ正確に行うことができ、競争優位性を確保したい場合に有効です。
簡単な操作性
Apache Sparkの操作性は非常にシンプルで、プログラミングの初心者にも扱いやすい設計となっています。 特に、PythonやScalaなどの言語でのAPIが提供されているため、データサイエンティストやエンジニアが既存のプログラミングスキルを活かして容易に作業を開始できます。
たとえば、簡単なコマンドでデータの読み込みや変換、集計を行うことができ、これらのプロセスを簡単にスクリプト化して再利用することが可能です。これにより、複雑なデータパイプラインの構築も容易になり、生産性の向上に寄与します。
スケーラビリティ
Apache Sparkはそのスケーラビリティにおいても非常に優れており、小規模なデータセットから数ペタバイト規模のデータセットまで、様々なサイズに対応することができます。 これは、クラスタ上で動作する設計によるもので、必要に応じて計算リソースを動的に追加または削除することが可能です。
たとえば、企業が急速にデータ量が増加した場合でも、Apache Sparkを使ってリソースを柔軟にスケーリングすることで、一貫した処理速度を維持することができます。このスケーラビリティは、ビッグデータ時代の企業にとって非常に重要な特性です。
Apache Sparkのアーキテクチャとコンポーネント
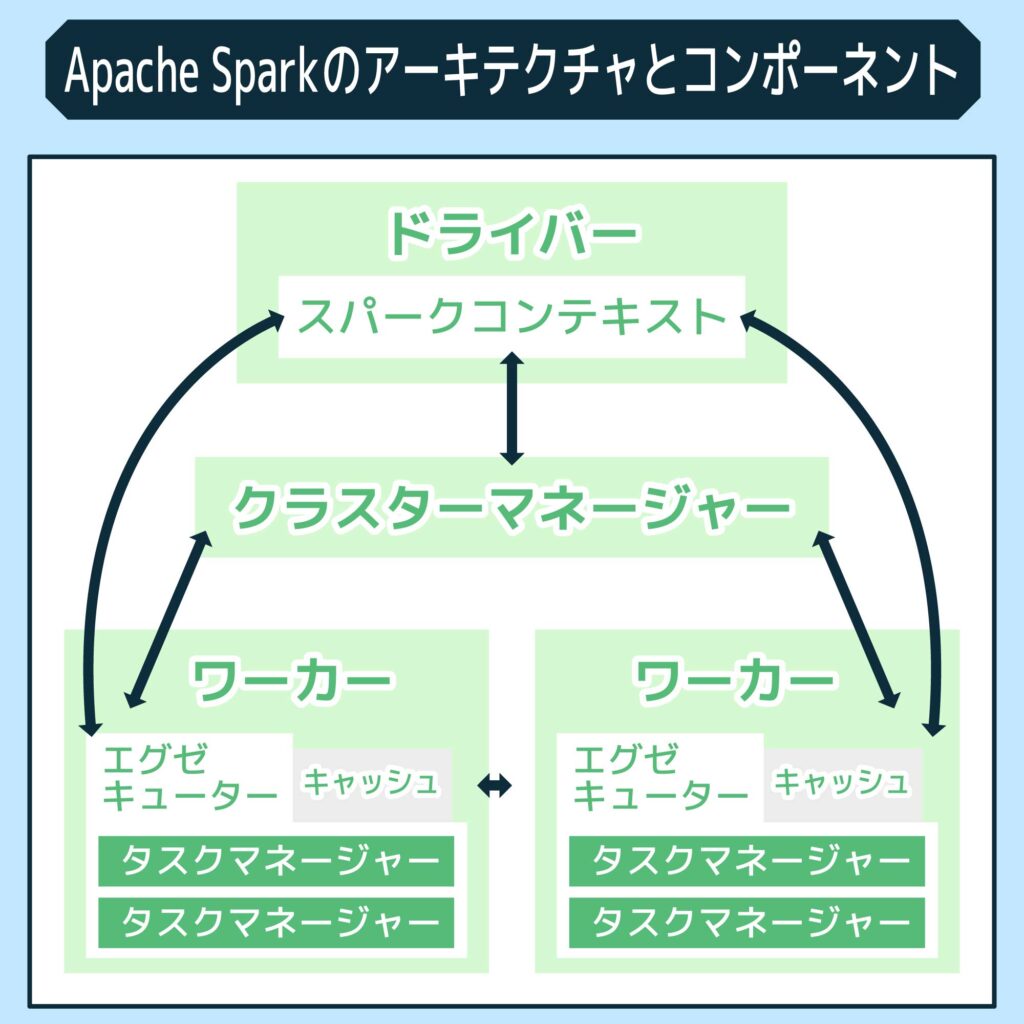
Apache Sparkのアーキテクチャは、複数の重要なコンポーネントで構成されています。 具体的には、以下のようなものが含まれています。
- ドライバー
- ワーカー
- エグゼキューター
- タスクマネージャー
ここでは、それぞれの特徴や役割について詳しく解説します。
ドライバー
ドライバーはApache Sparkのコアコンポーネントで、アプリケーションの管理と制御を担当します。 このコンポーネントは、全体のタスクスケジューリング、タスクの実行状態の監視、および失敗したタスクのリスタートなどを行います。
たとえば、データ分析アプリケーションが起動されると、ドライバーは入力データを読み込み、どのようにデータを処理し、どのノードでタスクを実行するかの計画を立てます。このプロセスを通じて、効率的かつ効果的にデータを処理することが可能になります。
ドライバーの機能は、特に大規模なデータセットを扱う際にその真価を発揮し、複雑な計算を短時間で完了させることができます。このように、ドライバーはSparkアプリケーションの性能と安定性を大きく左右する重要な役割を果たします。
ワーカー
ワーカーはApache Sparkのアーキテクチャにおいて、タスクの実行を行う基本的な単位です。 クラスタ内の各ノードに存在し、ドライバーから送られた指示に従って具体的なデータ処理タスクを実行します。
たとえば、大規模なデータセットの分析を行う場合、ドライバーはこのデータを小さなチャンクに分割し、それぞれのワーカーに割り当てます。
ワーカーはこれらのチャンクを独立して処理し、結果をドライバーに送り返します。 この分散処理により、大量のデータも高速に処理することが可能になります。
ワーカーの効率的な動作は、Sparkが高速データ処理を達成する上で中心的な役割を担います。これにより、リアルタイム分析やビッグデータの処理が実現され、企業の意思決定や戦略立案が迅速に行われます。
エグゼキューター
エグゼキューターはApache Sparkのアーキテクチャで、ワーカーノード上で直接タスクを実行するコンポーネントです。 ドライバーから受け取ったタスクを実行し、その結果をドライバーに返送する役割を持っています。
エグゼキューターの最も大きな特徴は、それぞれが独立してタスクを管理し、複数のタスクを並行して実行できることです。たとえば、データフィルタリングや集計などの操作を同時に行うことができ、これにより全体の処理速度が向上します。
この並行処理能力は、大量のデータを迅速に処理する際に非常に有効で、データ駆動型の意思決定を加速させます。 エグゼキューターは、効率的なリソース管理と高速処理を実現するためのキーテクノロジーと言えるでしょう。
タスクマネージャー
タスクマネージャーはApache Sparkで、エグゼキューターによって実行される各タスクの進行を管理します。 このコンポーネントは、タスクの進行状態を追跡し、エラー発生時にはリカバリー処理を行う責任を持っています。
たとえば、あるタスクが失敗すると、タスクマネージャーはそのタスクを再スケジュールし、別のエグゼキューターで再実行を試みます。これにより、全体の処理の信頼性が保たれ、システムのダウンタイムを最小限に抑えることができます。
タスクマネージャーの効率的な管理は、大規模なデータ処理の安定性を保ちながら、パフォーマンスを最大化するために不可欠です。これにより、データ処理タスクがスムーズに進行し、結果的にビジネスの迅速な意思決定に寄与します。
Apache Sparkを使ったデータ処理

Apache Sparkを使ったデータ処理は、その高速性とスケーラビリティで知られています。 このフレームワークは、ビッグデータのバッチ処理からリアルタイム分析まで幅広く対応しています。
ここでは、実際にApache Sparkを使ってどのようにデータを処理するかといった、具体的なプロセスを紹介します。
- データの読み込みと処理
- スケーリングとパフォーマンスの最適化
それぞれ詳しく解説するので、ぜひ参考にしてみてください。
データの読み込みと処理
Apache Sparkでのデータの読み込みと処理は、効率的で拡張性が非常に高いため、大量のデータセットを素早く扱うことができます。
Sparkは多様なデータソースからデータを読み込む能力を持っており、HDFSやS3、RDBMSなど、さまざまなストレージシステムに対応しています。
たとえば、Sparkを使用してソーシャルメディアのデータを分析する場合、膨大な量のデータを短時間で読み込み、リアルタイムで感情分析を実施することが可能です。
また、データの読み込み、フィルタリング、集計といった一連の操作がシームレスに行われることも特徴です。
このようにして、Apache Sparkは素早く情報を提供し、企業が情報にもとづいた意思決定を行うのをサポートします。
スケーリングとパフォーマンスの最適化
Apache Sparkのスケーリングとパフォーマンスの最適化は、クラスタ管理とリソース配分によって実現されます。
このフレームワークは、動的なリソーススケーリングをサポートしており、処理すべきデータ量に応じて、クラスタのリソースをリアルタイムで調整することが可能です。
たとえば、販売ピーク時のトランザクションデータ処理において、Sparkは追加のノードをクラスタに自動的に割り当てることで、データ処理能力を増強します。このように柔軟にスケーリングを行えるため、パフォーマンスを維持しつつ効率的にビッグデータの課題解決を行うことができます。
まとめ:ビッグデータを扱うならApache Spark

この記事では、Apache Sparkの特徴やメリット、具体的な使用方法について詳しく解説しました。
Apache Sparkはその高速性、スケーラビリティ、柔軟性が魅力であり、ビッグデータ処理の最前線で広く活用されています。
インメモリ計算を活用し、リアルタイム分析からバッチ処理まで可能にするこのフレームワークは、意思決定を素早く正確に行うための強力なツールとなるでしょう。
さまざまなビジネスでApache Sparkが活用できるので、今回の内容も参考に、ぜひ貴社の問題解決で活用してみてください。
また、Jiteraでは、ビジネスの課題を解決するツール開発の相談を受け付けています。お客様のお悩みに特化したツール制作に携わらせていただきますので、この機会にぜひお問い合わせください。




