

AI技術の進化は止まりません。その中でも、拡散モデルは画像生成技術の新たな可能性を開くものであり、その応用範囲は日々広がりを見せています。
この記事では、拡散モデルの考え方、仕組みから種類、特徴、実装方法に至るまでを詳細に掘り下げて解説します。
また、拡散モデルがどのように活用されているのか、具体的な事例を通じて紹介します。AIや画像生成技術に興味のある方は、ぜひ参考にしてください。
東京都在住のライターです。わかりづらい内容を簡略化し、読みやすい記事を提供できればと思っています。
拡散モデルとは何か?
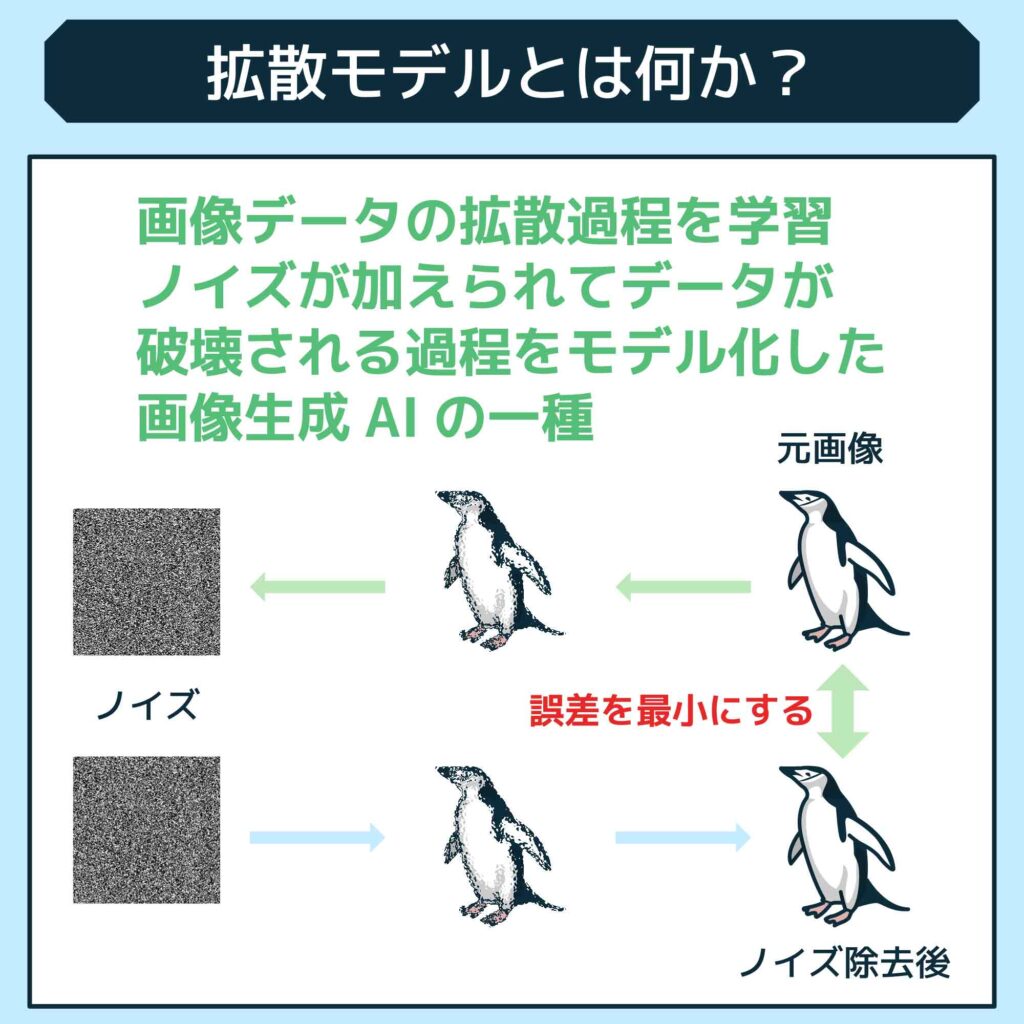
拡散モデル(Diffusion Model)は、画像データの拡散過程を学習し、ノイズが加えられてデータが破壊される過程をモデル化した画像生成AIの一種です。
まずは、拡散モデルの役割と仕組みを詳しくみていきましょう。
拡散モデルの役割
拡散モデルは、高次元データの生成において重要な役割を果たしています。画像生成AIや他の生成モデルの学習において革新的な進歩をもたらしており、特に、Stable DiffusionやDALL-E2などの技術が拡散モデルを基盤として、画像生成の品質や多様性を向上させています。
また、潜在変数モデルに基づく生成モデルであり、観測データから潜在変数を推定することで学習が行われます。この過程は専門的には「デノイジングスコアマッチング」と呼ばれるタスクを通じて、実現可能です。
画像生成AIの学習において重要な位置を占めており、GAN(敵対的生成ネットワーク)やTransformerなど他の技術と組み合わせることで高度な画像を生成することができる技術です。
拡散モデルの仕組み
画像データの拡散過程、つまりは、ノイズが加えられてデータが破壊される過程を学習することで、新しい画像データを生成する能力を持っています。
具体的には、元の画像にノイズを加えて画像全体をノイズの状態に変換させます。このノイズ化したデータを逆に適用させることで、元の画像データを復元したり、新たな画像データを生成させることが可能です。
より詳しく紹介すると、拡散モデルは「Forward process」と「Reverse Process」の2つのプロセスによって構成されます。Forward processでは元画像にノイズを加えて変換し、Reverse Processでは逆にノイズ化したデータから元の画像を再構築することで学習が行われます。
似たような仕組みとして、GAN(敵対的生成ネットワーク)という技術がありますが、両者には違いがあります。
まず、GANは本物と偽物のデータを対比させることで学習し、高品質で鮮明な画像生成に優れていますが、デメリットとして、学習が不安定で多様性に欠ける課題があります。
一方、拡散モデルは元画像情報から学習するため、高品質で幅広い表現を生み出せる技術です。ただし、計算コストがかかる点や、一部のモデル(データが少ない場合など)では不安定になることがあります。
状況に応じて適切な手法を活用することが大切です。
拡散モデルの種類と特徴
拡散モデルには様々な種類があります。ここでは、各モデルの種類と特徴について紹介します。
伝染病拡散モデルと情報拡散モデルの違い
まず、伝染病拡散モデルは、感染症の伝播過程をモデル化するために使用されます。主な目的は、感染症の拡散パターンや影響を予測し、適切な対策や制御策を検討することです。医療や公衆衛生の分野で広く利用され、感染症の予防や制御に役立ちます。
一方、情報拡散モデルは、情報やメッセージの拡散過程をモデル化するために使用されます。主な目的は、ソーシャルメディアやマーケティング分野で情報の拡散パターンや影響力を理解し、効果的な戦略を策定することです。
グラフ理論に基づく拡散モデルとその特性
グラフ理論に基づく拡散モデルは、機械学習分野における潜在変数モデルの一種であり、拡散確率モデルとも呼ばれます。
このモデルは、グラフ理論と深層ニューラルネットワークの技術を組み合わせた統合モデルであり、VAE(Variational Autoencoder)などとも非常に近いです。
具体的には、確率グラフィカルモデル(Probabilistic Graphical Model)と深層ニューラルネットワークを組み合わせて構築されます。学習した分布から潜在変数をサンプリングし、ニューラルネットワーク上で変換する生成プロセスが行われます。
VAEと同様に、入力を潜在空間上の特徴量で表すエンコーダと、潜在空間から元の次元に戻すデコーダで構成されており、潜在空間には分布が仮定されます。
拡散モデルの実装方法

次に、拡散モデルの実装方法についてみていきます。主に以下の手順で実装することが可能です。
- 事前準備
- 画像の読み込み
- ノイズの追加
- ノイズを除去
- 学習
- サンプリング
それぞれ詳しくみていきましょう。
事前準備
拡散モデルの実装には、まず必要なライブラリやツールを準備する必要があります。Pythonを主としたプログラミング環境を使用します。
以下は、一般的に必要なライブラリやツールのインストール手順の例です。ここでは、主にPyTorchとNumPyを使用します。
pip install torch torchvision
NumPyは、Pythonの数値計算を効率的に行うためのライブラリです。行列計算などの高度な数値計算をサポートしています。
PyTorchは、Python向けの深層学習フレームワークの一つで、GPUを利用した計算が可能です。拡散モデルの実装には、ニューラルネットワークの構築や学習、予測などを行うために必要です。
これらのライブラリをインストールしたら、次に実際のコードを書いていくことになります。
画像の読み込み
画像の読み込みには、Pythonの画像処理ライブラリであるPIL(Python Imaging Library)を使用します。PILをインストールしていない場合は、以下のコマンドでインストールできます。
画像の読み込みは以下のように行います。
import numpy as np# 画像の読み込み
img = Image.open(“image_path.png”)# 画像をnumpy配列に変換
img_array = np.array(img)
画像をnumpy配列に変換することで、画像の各ピクセルの色情報を数値データとして扱うことができます。これにより、画像にノイズを加える等の処理を行う準備が整います。
また、モデルの入力として使用するためには、一般的には画像データを正規化(各ピクセルの値を0~1の範囲にする)します。
img_array = img_array / 255.0
これらの手順により、画像の読み込みと前処理を行うことができます。
ノイズの追加
ノイズの追加は、拡散モデルの学習過程で重要なステップです。元の画像データにランダムなノイズを加え、そのノイズ化したデータを学習することで、モデルは元の画像データを再構築する能力を獲得します。
PythonのNumPyライブラリを使って画像にランダムノイズを追加することができます。以下はその一例です。
import numpy as np
# ノイズを生成する関数
def add_noise(image, noise_factor=0.5):
noise = np.random.normal(loc=0.0, scale=noise_factor, size=image.shape)
noisy_image = image + noise noisy_image = np.clip(noisy_image, 0., 1.)
return noisy_image
# 画像にノイズを追加
noisy_image = add_noise(img_array)
このコードでは、add_noise関数を使って元の画像にノイズを追加しています。noise_factorはノイズの強度を制御するパラメータで、これを調整することで、ノイズの量を変えることができます。
ノイズを除去
ノイズを除去するためには、一般的にはデノイジング(ノイズ除去)手法を使います。この手法は、ノイズが混じったデータから元のクリーンなデータを復元するためのものです。
以下は、Pythonと深層学習フレームワークの一つであるPyTorchを使ったデノイジングの一例です。ここでは、深層学習モデル(Denoising Autoencoder)を使ってノイズを除去しています。
mport torch
import torch.nn as nn
# デノイジングオートエンコーダモデルの定義
class DenoisingAutoencoder(nn.Module):
def __init__(self):
super(DenoisingAutoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28 * 28, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 12),
nn.ReLU(),
nn.Linear(12, 3) # latent space
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.ReLU(),
nn.Linear(12, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 28 * 28),
nn.Sigmoid() # to get the pixel values in range [0, 1]
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
# モデルのインスタンス化
model = DenoisingAutoencoder()
# 損失関数と最適化アルゴリズムの定義
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# 入力データにノイズを加える
noisy_data = add_noise(input_data) # Assume add_noise function and input_data are defined
# デノイジングの実行
model.train()
for epoch in range(100): # Assume we train for 100 epochs
optimizer.zero_grad()
outputs = model(noisy_data)
loss = criterion(outputs, input_data) # We want our output to be as close to the original clean input_data as possible
loss.backward()
optimizer.step()
# ノイズ除去後のデータを取得
model.eval()
denoised_data = model(noisy_data)
このコードでは、デノイジングオートエンコーダという深層学習モデルを定義し、ノイズが混じったデータから元のデータを復元しています。学習後、model.eval()とmodel(noisy_data)を使ってノイズを除去したデータを生成します。
学習
拡散モデルの学習では、ノイズを除去したデータと元のデータが一致するようにモデルを訓練します。このために、一般的には損失関数として平均二乗誤差(MSE)を使用します。訓練は以下のように行います。
# 学習の設定
epochs = 100
for epoch in range(epochs):
model.train() # モデルを訓練モードに設定
# バッチごとの訓練
for batch in dataloader: # dataloaderは訓練データをバッチに分割して提供します
# データをGPUに送る
batch = batch.to(device) # deviceはCPUまたはGPUを指します
# モデルの出力を計算
outputs = model(batch)
# 損失を計算
loss = criterion(outputs, batch) # criterionは損失関数(例えば、nn.MSELoss())を指します
# 勾配をゼロに初期化
optimizer.zero_grad()
# 逆伝播を行い、勾配を計算
loss.backward()
# パラメータを更新
optimizer.step()
# 学習結果の保存(必要に応じて)
torch.save(model.state_dict(), “model.pth”)
このコードでは、元のデータ(batch)とデノイジング後のデータ(outputs)の間の損失を計算し、それを最小化するようにモデルのパラメータを更新しています。
この学習を繰り返すことで、モデルはノイズを除去し、元のデータを再構成する能力を学びます。
サンプリング
サンプリングは、拡散モデルの学習が終わった後のステップで、ここではモデルを用いて新たなデータを生成します。このプロセスでは、何度も繰り返し行うことで、推論のレベルを高めることができます。
具体的には、最初にノイズのみから始めて、その後逆拡散プロセスを用いて元のデータを逐次的に再構成します。このとき、各ステップでは条件付き確率分布からのサンプリングが行われ、これを繰り返すことで元のデータを復元します。
この繰り返しプロセスが重要なのは、各ステップでのサンプリングが次のステップの入力となり、それによって推論の精度が逐次的に向上していくからです。つまり、サンプリングの繰り返しによって、モデルはより正確なデータを生成する能力を獲得するのです。
拡散モデルの応用

拡散モデルはどのように応用されているのでしょうか?ここでは、2つの事例を紹介します。
拡散モデルを使用した画像生成「Stable Diffusion」
「Stable Diffusion」は、拡散モデルの一種であり、入力したプロンプトに基づいて画像を生成するサービスです。従来の深層学習(ディープラーニング)を応用した敵対的生成ネットワーク(GAN)と比較して、品質が安定しやすく、高品質な画像生成に優れています。
Stable Diffusionは広告や雑誌などで使用するヴィジュアルを作成する際に利用されています。リアルな画像を生成するだけでなく、イラストやQRコードの作成、画像編集など様々な用途に適用されています。AI技術の進化によって実用化されつつあり、高品質かつ多様な画像生成ニーズに応える重要な技術として注目されている技術です。
拡散モデルを用いた異常検知と予測の応用例
拡散モデルは異常検知や予測にも用いられます。たとえば、作成した画像が要件を満たしているかを確認する場合に役立つ機能です。
具体的には、入力画像と再構成画像の差異を評価し、異常スコアを計算します。このスコアが高いほど、入力画像は異常である可能性が高くなります。設定された閾値に基づいて、異常スコアが閾値を超えるかどうかで入力画像が異常かが判断され、判別できるのです。
閾値を超えた場合、その入力画像は異常として検知されます。
拡散モデルと機械学習の関連性

拡散モデルは、生成モデルによる異常検知などの応用で機械学習技術と結びつき、画像生成や異常検知などの分野で革新的な成果を生み出しています。また、AIと人間の関係性や複数のAI間の相互作用についても考える研究が行われており、新たな展開が期待されているでしょう。
ここでは、拡散モデルと機械学習の関連性について深掘りします。
拡散モデルと機械学習手法の統合と活用
拡散モデルを使用した異常検知では、生成モデルによる異常検知手法が一般的です。この手法では、正常画像のみで学習したモデルを使用し、入力画像と再構成画像の差異を評価して異常画像を検知します。非常に効果的な異常検知手法として活用されています。
たとえば、工場における部品の製造工程において、正常な画像と見比べて差異があるか、そしてどの程度の差異なのかを判別し、閾値を超えたものについては弾くことが可能です。
未だ発展途上の分野ですが、AI技術の進化や新たな研究成果を生み出す一助となると期待されています。
拡散モデルを用いたAIシステムの開発と応用
拡散モデルを用いたAIシステムの開発は、社会現象の予測や理解に大きな可能性を秘めています。
たとえば、時間とともに変化するシステムの動作を分析・予測する確率モデルとして活用することで、株式市場のリターン予測やパンデミック蔓延の予測にも応用されています。
また、拡散モデルを音声認識のために使うと、異常な音が発生した際に認識し、事前に災害の兆候を見分けられる可能性があるでしょう。このように、分野を超えてさまざまなシーンで活用しているのが「拡散モデル」です。
拡散モデルに関する解説書籍〜『拡散モデル データ生成技術の数理』〜

「拡散モデル データ生成技術の数理」は、高次元データの生成に注目される拡散モデルに焦点を当てた書籍です。この本は岡野原大輔氏によって執筆され、2023年2月21日に岩波書店から発売されました。
この書では、拡散モデルの数理的背景から応用まで幅広く解説されています。特に、生成品質の高さや多様な用途だけでなく、従来の生成モデルにはない高い拡張性を強調する記述が多いです。
Stable Diffusionや他の生成モデルに興味がある人や、数学的背景や応用先に興味がある読者におすすめです。また、機械学習系の本でも分かりやすく数式が記載されているので、実践的な内容となっています。
拡散モデルの数理的側面からその応用まで包括的に解説しているため、生成モデルや機械学習に興味を持つ読者にとって有益な情報源となるでしょう。
自然言語モデルのまとめ

この記事では、拡散モデルの考え方、仕組みから種類、特徴、実装方法に至るまでを詳細に掘り下げて解説しました。
拡散モデルは、生成モデルの一種であり、画像生成や異常検知など様々な分野で利用されています。拡散モデルを使用した画像生成サービス「Stable Diffusion」は、昨今話題沸騰中でありますが、その技術の基礎となる部分がご紹介した「拡散モデル」です。
今回、コードでの実装方法を含めて紹介しましたが、非常に専門的な内容であるため、本格的に実装したい場合にはAIの専門家に相談することをおすすめします。
株式会社Jiteraでも、AIの実装支援やコンサルティングをお受けしているので、興味がある方は是非お問い合わせください。また、今回の内容に関しての質問、疑問、お悩みもお気軽にご相談ください。



