

機械学習の分野において、次元削減は非常に重要な手法の一つです。次元削減とは、データの特徴を保ちつつ、そのデータをより少ない情報量で表現するプロセスのことを指します。この手法は、高次元データセットを扱う際に特に有効で、計算コストの削減、データの可視化、ノイズの低減、そしてモデルのパフォーマンス向上に貢献します。
本記事では次元削減の機械学習での重要性や仕組みなどの基礎をわかりやすく解説します。
東京在住、大手IT企業出身、Web業界10年以上のアラサーです。新規事業開発やシステム開発にプロジェクトベースで関与したりこれまでの経験をもとに執筆活動を行っています。
次元削減の概念

次元削減は、高次元のデータを低次元のデータに変換する手法です。次元削減手法を利用することで、多次元空間のデータをより少ない次元の空間に変換することができます。
次元削減とは
次元削減は、データの特徴を保ちつつ次元を減らすことを目的としています。多次元のデータは、データの解釈や可視化において困難を伴うことがあります。そのため、次元削減を用いてデータを低次元に変換することで、データの理解や解析を容易にします。
次元削減の必要性と用途
次元削減の必要性は、主に以下の2つの理由から生じます。まず一つ目は、次元削減によってデータを可視化することです。高次元のデータを可視化することは難しいため、次元を減らすことでデータをグラフや図形として表現することができます。これにより、データの特徴やパターンを視覚的に理解することができます。
二つ目は、次元削減によってデータの解析や処理を効率化することです。高次元のデータは計算や処理に時間がかかることがありますが、次元を削減することでデータのサイズを小さくすることができます。これにより、データベースの容量や計算資源の節約が可能となります。
次元削減は機械学習の他の手法とも組み合わせて利用することがあります。特徴選択や特徴抽出という手法と組み合わせることで、より効果的なデータの処理や学習が可能となります。
次元削減の概念について理解することで、機械学習やデータ解析の基礎を深く学ぶことができます。具体的な次元削減手法についても、後続の項目で詳しく解説します。
以上が、次元削減の概念についての解説です。次に、主な次元削減手法について説明します。
主な次元削減手法

次元削減手法にはさまざまな手法がありますが、その中でもよく用いられる手法をいくつか紹介します。
主成分分析 (PCA)
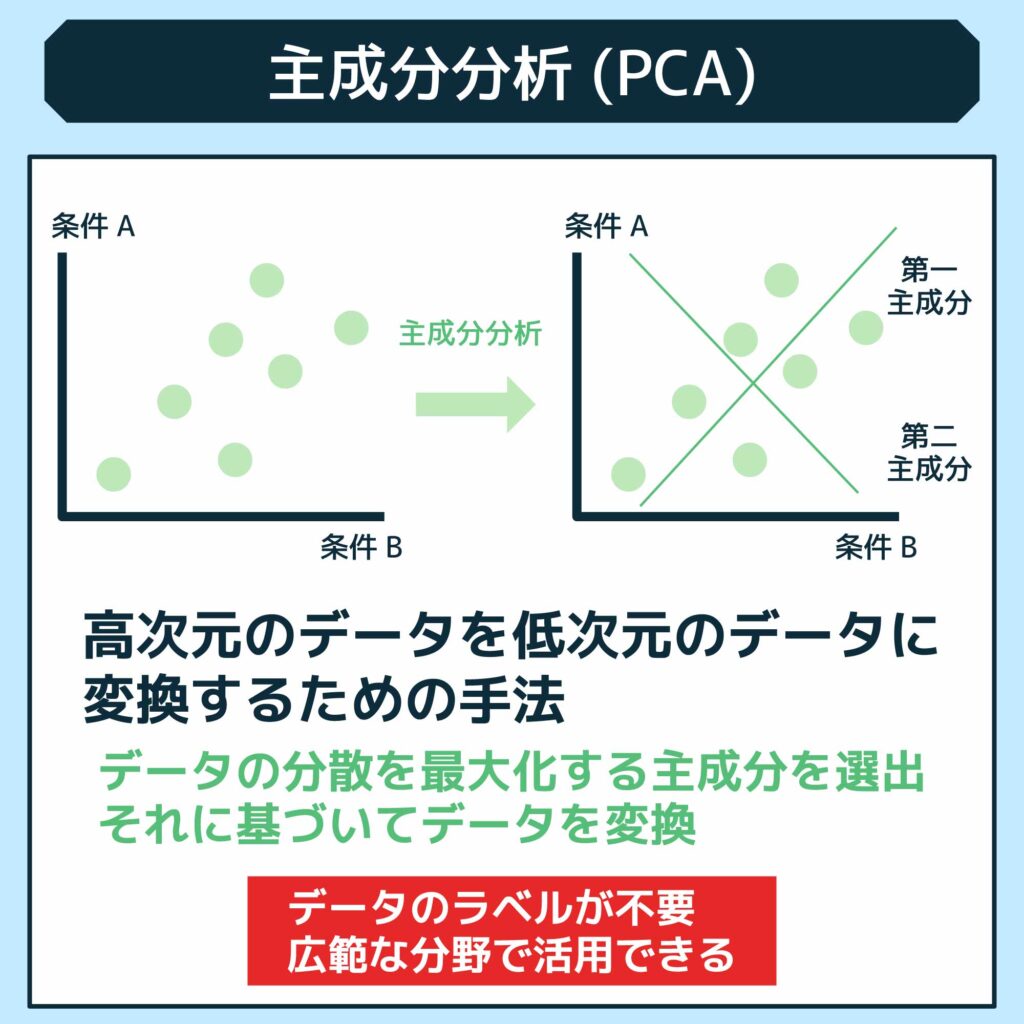
主成分分析(Principal Component Analysis、PCA)は、高次元のデータを低次元のデータに変換するための手法です。主成分分析では、データの分散を最大化する主成分を選び出し、それに基づいてデータを変換します。具体的には、与えられたデータセットの共分散行列を計算し、その固有値と固有ベクトルを求めます。そして、固有値が大きい順に固有ベクトルを選び出し、それに対応する主成分としてデータを再構築します。主成分分析は教師なし学習の一種であり、データのラベルが必要ないため広範な分野で活用されています。
主成分分析の利点は、データの次元を削減することで可視化やデータの圧縮ができることです。また、特徴選択法や特徴抽出法としても利用され、データの重要な特徴を抽出することができます。しかし、主成分分析は解釈が難しいことや非線形な関係性を捉えることができないという欠点もあります。さらに、次元削減によってデータの一部の情報が失われる可能性もあるため、注意が必要です。
t-SNE
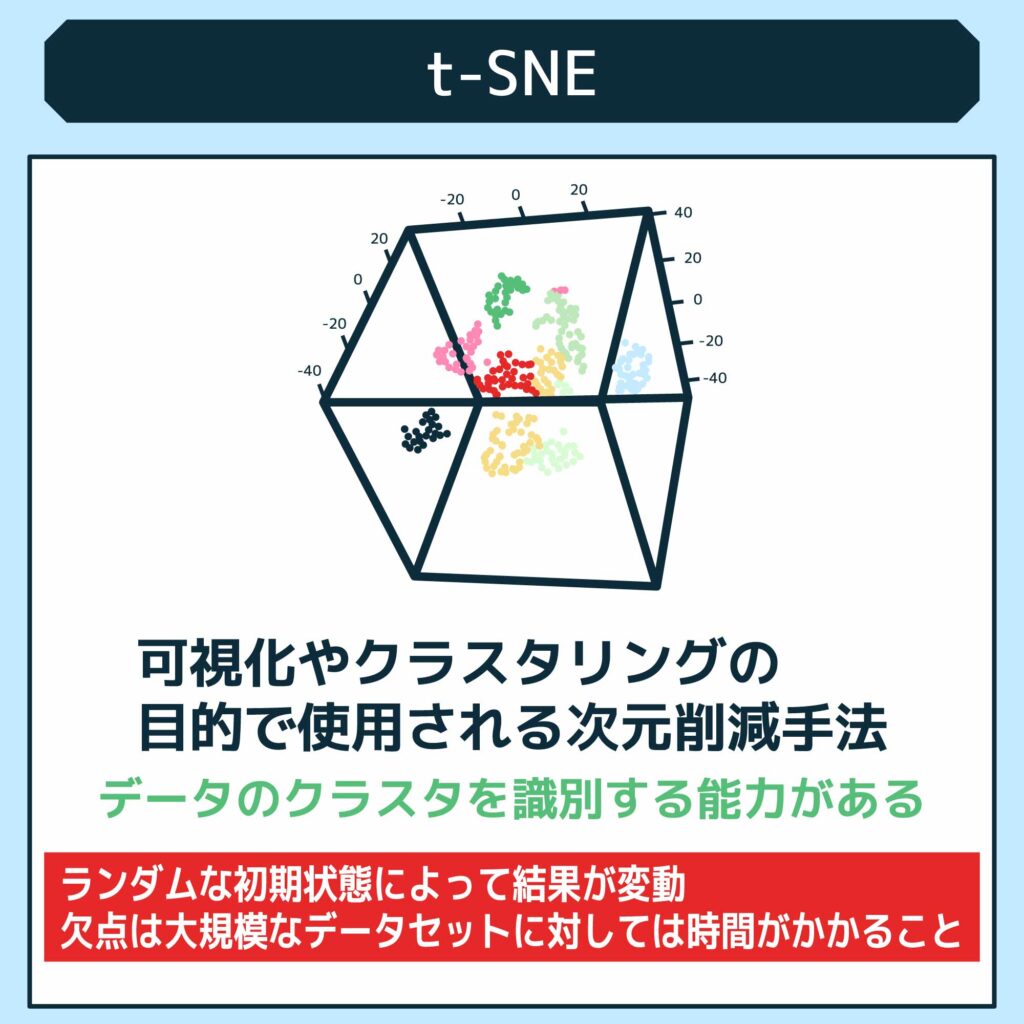
t-SNE(t-Distributed Stochastic Neighbor Embedding)は、主に可視化やクラスタリングの目的で使用される次元削減手法です。t-SNEは非線形の次元削減手法であり、高次元データの特徴を保持しつつ、低次元のデータ空間に埋め込むことができます。t-SNEは、類似したデータポイントを近くに配置するような性質を持っており、データの構造をより明確に見せることができます。
t-SNEの特徴として、データのクラスタを識別する能力があります。また、可視化においても優れた性能を発揮し、データの潜在的な特徴やパターンを視覚的に表現することができます。しかしながら、t-SNEはランダムな初期状態によって結果が変わることや、大規模なデータセットに対しては時間がかかるといった欠点も存在します。
UMAP
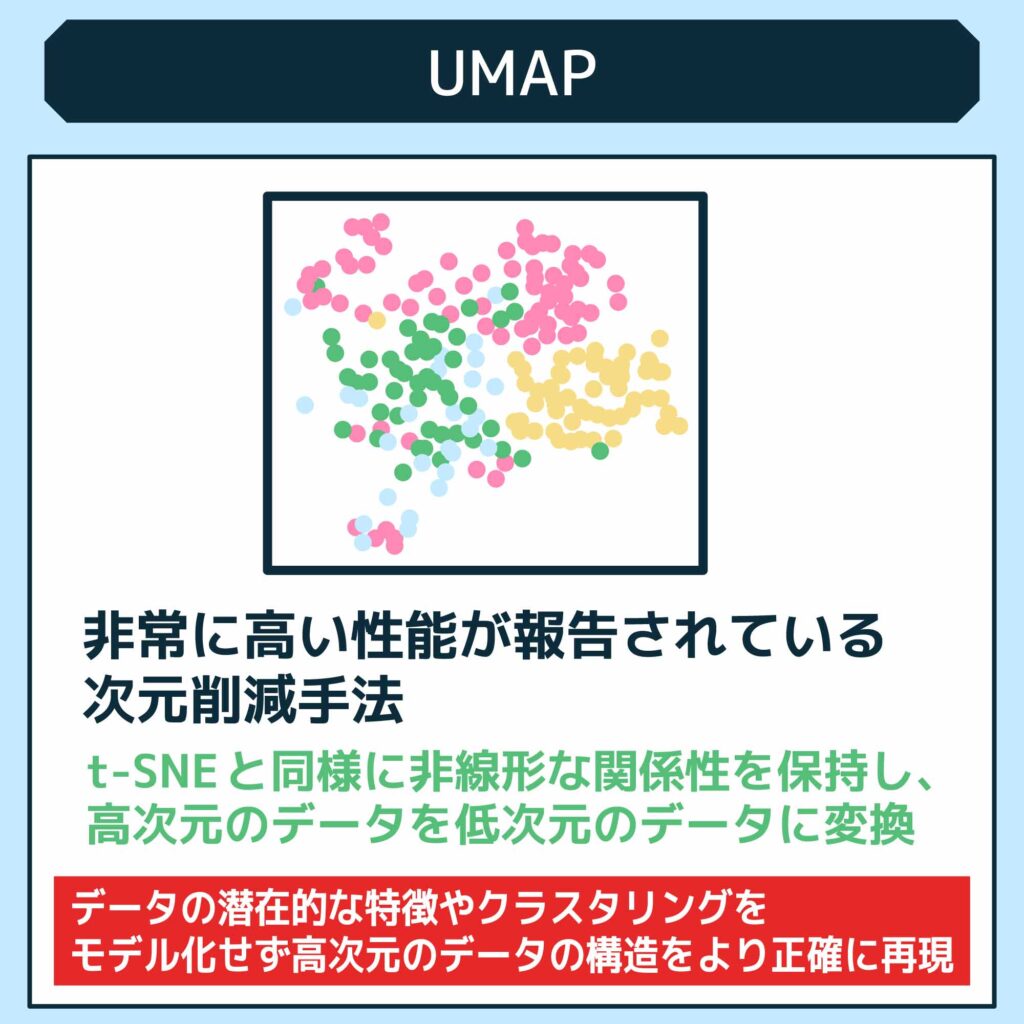
UMAP(Uniform Manifold Approximation and Projection)は、非常に高い性能が報告されている次元削減手法です。UMAPは、t-SNEと同様に非線形な関係性を保持しながら、高次元のデータを低次元のデータに変換することができます。UMAPは特に大規模なデータセットに対して効果が高く、高速でスケーラブルな手法として知られています。
UMAPの利点は、高い表現力を持ちながらもデータの潜在的な特徴やクラスタリングを明示的にモデル化しないことです。これにより、UMAPは高次元のデータの構造をより正確に再現することができます。また、UMAPは最適なパラメータを自動的に推定するため、手動でパラメータを調整する必要がありません。
UMAPの欠点としては、t-SNEと同様に初期状態によって結果が変わることや、特定のデータセットに対しては適用できないことがあります。さらに、UMAPの結果を解釈することが難しいという点も注意が必要です。
次元削減のメリットとデメリット

次元削減のメリットは、以下のような点があります。
- データの可視化が容易になる:高次元のデータを低次元に変換することで、データを図示する際の可視化の難しさを解消できます。可視化することで、データの特徴やパターンを直感的に理解しやすくなります。
- 計算コストの削減:高次元のデータでは計算コストが膨大になることがありますが、次元削減によってデータの次元数を削減することで、計算コストを削減できます。これにより、機械学習モデルの学習や推論の効率が向上します。
- ノイズの除去:次元削減によって低次元に変換することで、データの中に含まれるノイズや冗長な特徴を除去することができます。これにより、ノイズの影響を減らし、より精度の高い予測や分類ができるようになります。
一方、次元削減のデメリットも考慮する必要があります。
- 情報の損失:次元削減は、データの一部の情報を削除することになるため、元のデータに比べて情報の損失が生じます。これにより、予測や分類の精度が低下する可能性があります。
- 解釈の難しさ:次元削減によって得られた低次元のデータが元のデータとどのように関連しているのかを理解することが難しくなります。特に、非線形な関係性を持つデータの場合、解釈が難しくなる傾向があります。
以上が、次元削減のメリットとデメリットです。
次元削減の活用事例

次元削減は様々な領域で活用されており、以下に代表的な活用事例をいくつか紹介します。
データの可視化
次元削減は、高次元のデータを低次元のデータに変換することができるため、データの可視化に利用されます。高次元のデータは視覚的に理解しにくいため、次元削減によって得られた低次元データをプロットすることで、データの構造やパターンを把握することができます。
異常検知
次元削減は、異常検知においても活用されます。異常値は通常、他のデータ点からは孤立しているため、次元削減によりデータを低次元に変換することで、異常値を特定することができます。低次元に変換されたデータの中で、他のデータ点から距離が大きく離れているデータは異常値の可能性が高いと言えます。
特徴抽出
次元削減は機械学習の特徴抽出にも使用されます。特徴抽出は、データセットから重要な特徴を抽出し、それを入力として機械学習モデルに与えることで精度の向上を図る手法です。次元削減を行うことで、情報の損失を最小限に抑えつつ、ノイズや冗長な特徴を排除し、モデルの訓練や予測の効率性を高めることができます。
次元削減はこれらの活用事例において重要な役割を果たしており、データの特性や機械学習の性能向上に寄与しています。
次元削減と機械学習

次元削減は、機械学習において重要な概念です。データの次元を減らすことで、高次元のデータを扱いやすくし、モデルの学習や予測の効率を向上させることができます。
教師なし学習と次元削減
次元削減は、教師なし学習の一つとして利用されます。教師なし学習では、データにラベルが付いていないため、主成分分析などの次元削減手法を使ってデータの潜在的な構造やパターンを発見することができます。
主成分分析は、データの分散を最大化する主成分を選び出し、それに基づいてデータを変換します。このようにして、元のデータよりも少ない次元の特徴量でデータを表現することができます。
次元削減は、データの次元を減らすだけでなく、データの可視化にも利用されます。可視化によって、データの傾向や関連性を直感的に理解することができ、データの解釈や意思決定に役立ちます。
次元削減と特徴選択
次元削減には、特徴選択という手法も存在します。特徴選択は、与えられたデータセットから最も重要な特徴を選択し、それ以外の特徴を削除することです。
特徴選択は、次元削減の一種であり、特徴量の数を減らすことで、計算コストや過学習のリスクを軽減し、モデルの性能を向上させることができます。特徴選択には、フィルタリング法やラッパー法、埋め込み法などがあります。
フィルタリング法は、特徴量同士の関連性や重要度を統計的に評価し、それに基づいて特徴を選択する手法です。ラッパー法は、特徴の組み合わせを試しながら予測性能を最大化する特徴を選択する手法です。埋め込み法は、モデルの学習プロセスで特徴の重要度を評価し、それに基づいて特徴を選択する手法です。
特徴選択は、次元削減手法の一つとして使用されるため、機械学習のパフォーマンス向上に役立つ重要な手法です。
まとめ

次元削減は、機械学習において重要な手法です。次元削減を行うことで、高次元のデータを低次元のデータに変換することができます。
主成分分析(PCA)やt-SNE、UMAPなどの主な次元削減手法があります。これらの手法は、データの圧縮や可視化に使われます。
主成分分析は、データの分散を最大化する主成分を選び出し、データを変換します。これにより、データの特性を保持しながら次元を減らすことができます。
次元削減は教師なし学習の一種であり、データのラベルが必要ありません。そのため、様々な分野で利用されています。
次元削減の欠点としては、解釈が難しいことや非線形な関係性を捉えることができないことが挙げられます。また、次元削減はデータの一部の情報を失ってしまう可能性があるため、注意が必要です。
次元削減は、機械学習においてデータの理解や解析をする上で重要な役割を果たします。適切な次元削減手法を選び、データを効果的に活用していきましょう。
この記事では次元削減の基礎知識をご紹介しました。次元削減についてまずはどのようなものか理解したいと考えている方にとって、参考になりましたら幸いです。
次元削減に代表される機械学習の応用、開発、技術選定など開発課題をお持ちの方はぜひ一度Jiteraまでご相談ください。



