CONTEXT
会社のルールや情報を、AIに覚えさせる。
プロジェクトの背景、チームのルール、過去の意思決定。こうした社内の情報をAIに学ばせることで、「うちの会社の事情を知った上で答えてくれるAI」が実現します。

プロジェクト背景
チームルール
過去の意思決定
社内用語集
セキュリティポリシー
社内の知識・ルール・業務データをコンテキストとして学習し
AI Readyな基盤を築くJitera

導入実績











Solutions
「AIを使いたいが、どこから始めればいい?」という段階から、大規模なシステム刷新まで。
企業のAI活用に関わる課題をまとめてサポートします。
営業・サポート・バックオフィスなど、繰り返し発生する業務をAIに任せられます。「毎回同じ説明をしている」「確認作業に時間がかかる」といった悩みを解消します。
チームがAIをバラバラに使っていて、情報漏えいや品質のばらつきが心配な方へ。誰が何をAIに聞いたかを記録し、会社として安全にAIを使える環境を整えます。
「10年以上前のシステムで、中身を知っている人がいない」という状況をAIが解析。仕様書の作成から新しいシステムへの移行まで、コストと時間を大幅に削減します。
業界・業務に特化した非公開のサービスラインナップもご用意しています。詳細は営業担当より直接ご案内します。
Platform Features
社内情報の学習から、業務の自動化、外部ツールとの連携、セキュリティ管理まで。 AIを「使えるもの」にするために必要な機能を、ひとつにまとめました。
CONTEXT
プロジェクトの背景、チームのルール、過去の意思決定。こうした社内の情報をAIに学ばせることで、「うちの会社の事情を知った上で答えてくれるAI」が実現します。
AI DOCS
「ドキュメントを書く時間がない」問題をAIが解決。システムの仕様書やテスト設計書などを自動で生成・更新します。
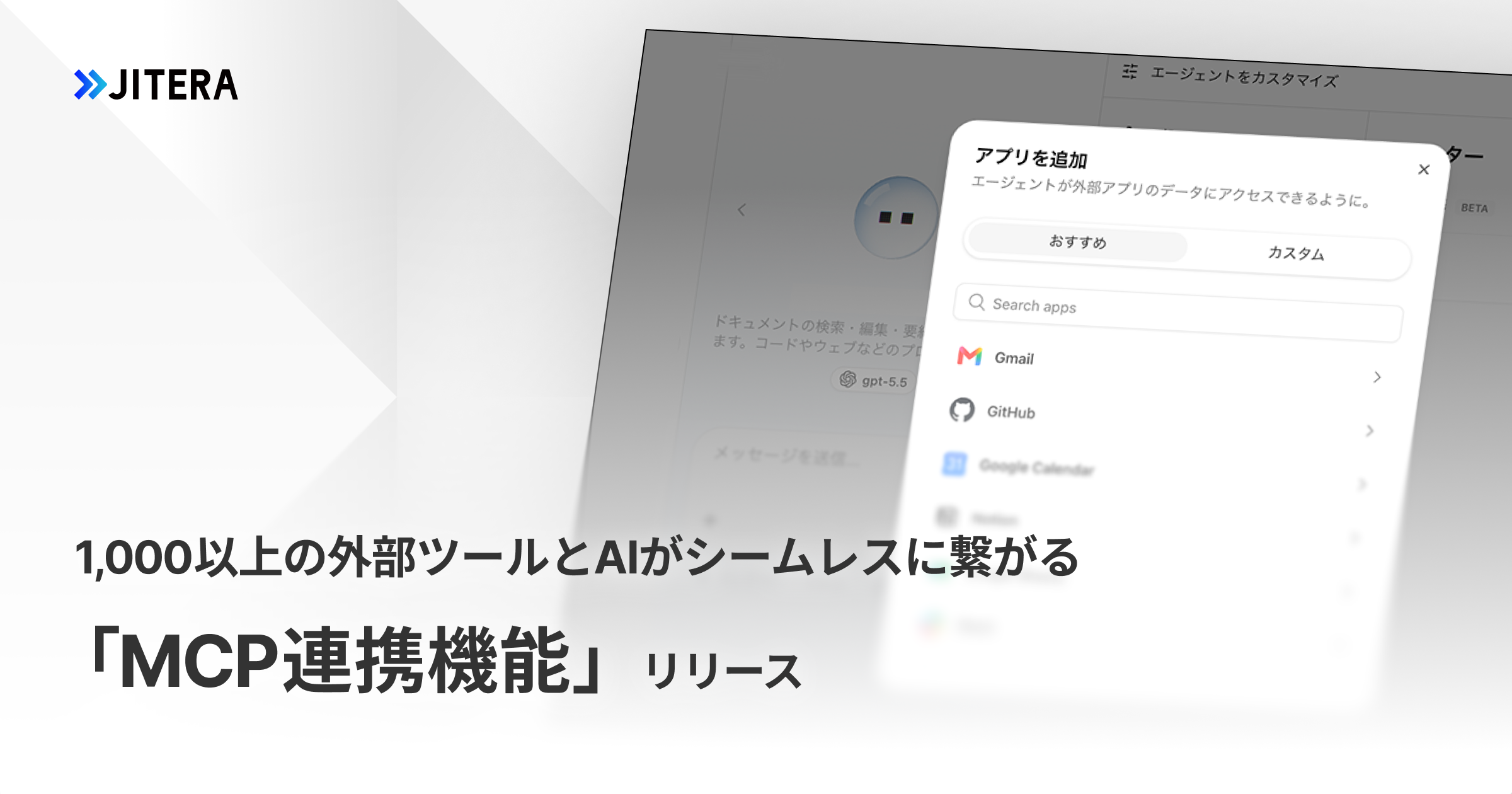
MCP
GitHub・Slack・Notion・Jiraなど、すでに使っている社内ツールをAIから直接操作できます。ツールを切り替える手間がなくなります。
AGENT BUILDER
役割・ツール・ガードレールを定義するだけで、業務特化エージェントを構築。
CASE STUDIES
「本当に自社で使えるの?」という疑問に、実際の導入事例でお答えします。
設計書のないレガシーシステムのリバースエンジニアリングと運用保守の効率化をAIで実現。ドキュメント作成時間を大幅短縮。

属人化していたベテラン開発者の暗黙知をAIエージェントに学習させ、組織のナレッジ資産として再利用可能に。

半導体測定装置の制御ソフトをJiteraで近代化。レガシーコードの解析工数を50%削減し、処理速度を20倍に向上。